深度学习训练营课程笔记。
References
逻辑回归
逻辑回归的内容可以回顾这里:机器学习初等指南(1)-逻辑回归。
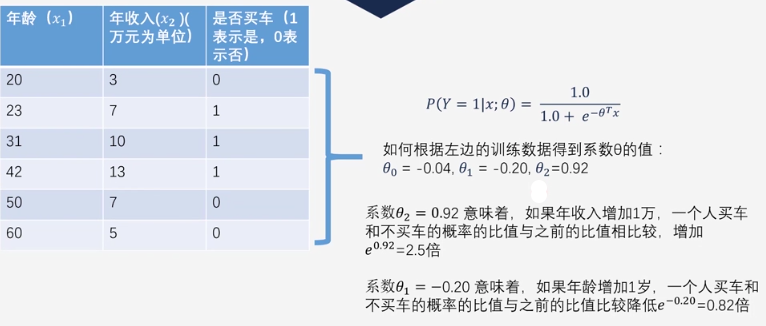
Ex:利用年龄和收入预测是否买车。

1 | from sklearn import linear_model #引入sklearn线性模型 |
拟合系数的含义
则概率比值$odds=\frac{p}{1-p}=e^{\theta^Tx}$。
$系数\theta_j意味着,假设odds为\lambda_1(原),\lambda_2(新),若x_j增加1,有\cfrac{\lambda_2}{\lambda_1}=e^{\theta_j}$。
以下是验证程序:
1 | from sklearn import linear_model #引入sklearn线性模型 |
应用案例
参考程序:spam_detection.ipynb, 垃圾短信检测数据集.zip
示例代码
在hexo中写的文章支持jupyter-notebook显示| 幻悠尘的小窝
注意需要
npm install co。太偏右修正:https://github.com/qiliux/hexo-jupyter-notebook/issues/3。
核心代码:
document.getElementById('ipynb').style['margin-left'] = '-60px';
简单代码
1 | import pandas as pd |
神经网络
神经网络的内容可以回顾这里:机器学习初等指南(2)。
鸢尾花分类
https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
【python数据挖掘课程】十九.鸢尾花数据集可视化、线性回归、决策树花样分析
Iris鸢尾花数据集可视化、线性回归、决策树分析、KMeans聚类分析
Iris plants 数据集可以从
KEEL dataset数据集网站获取,也可以直接从Sklearn.datasets机器学习包得到。数据集共包含4个特征变量、1个类别变量,共有150个样本。类别变量分别对应鸢尾花的三个亚属,分别是山鸢尾 (Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)分别用[0,1,2]来做映射。
1 | # -*- coding: utf-8 -*- |
一些知识

softmax存在数值问题。(中间有指数膨胀)
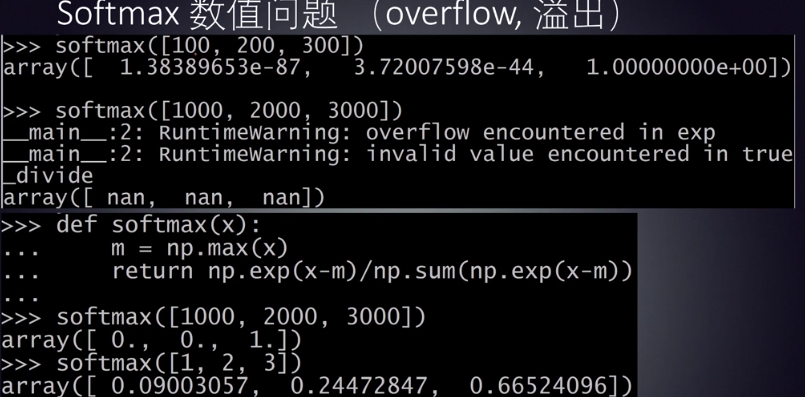
可以利用最大值偏置进行修正。避免溢出。
tanh函数:
深度神经网络
深度神经网络的两大挑战:
梯度消亡(Gradient Vanishing):训练过程非常慢。
过拟合(Overfitting):在训练数据上效果好,在测试数据集上效果差。
梯度消亡
神经网络靠近输入端的网络层系数变化不敏感。当网络层数增加时,现象更明显。
梯度消亡的前提:
- 使用基于梯度的训练方法
- 激活函数的输出值范围远小于输入值范围(
sigmoid、tanh、softmax)
实际上,对于这样的激活函数,100、10000和10005三者的激活值几乎一致。
如果一个(大)系数的微小变化对网络的影响很小,那么就很难进行优化(优化特别慢)。训练起来就很困难了。
可以想象的是,损失函数是一个非常平坦的凹面。
ReLU激活
ReLU:$f(x)=max(0,x)$。- 正值梯度。
LeakyReLU:$f(x)=max(ax,x)$。- 优化了负值梯度。
为什么不直接选择激活函数$f(x)=x$(恒同映射)?
激活函数一定要是非线性的。如果激活函数是线性函数,那么最后得到的就是一个线性分类器。
激活函数的非线性越强,那么分类能力也就越强。
非梯度训练方法

过拟合
解决方案:
DropoutL2正则化L1正则化MaxNorm
Dropout
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
【论文精读】Dropout: A Simple Way to Prevent Neural Networks from …,Atlas8346

Dropout可以被解释为一种通过在隐藏的单元中添加噪声来调节神经网络的方法。
大概意思就是引入神经元的休息状态。神经元有一定概率被Dropout,也就完全不能被激活,从而输出全为0。
L2正则化

L1正则化

MaxNorm

神经网络系数的初始化

实战项目1: 自动为图片生成描述 Image Captioning
环境安装参考:机器学习初等指南(1)-环境安装与使用
Task1 构建VGG16
经典的网络有:VGG, ResNet, DenseNet。
深度学习卷积神经网络——经典网络VGG-16网络的搭建与实现 …
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3 3的小型卷积核和2 2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降, VGGNet论文中全部使用了3 3的小型卷积核和2 2的最大池化核,通过不断加深网络结构来提升性能。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
Pre-卷积
A Comprehensive Introduction to Different Types of Convolutions in Deep Learning
如何理解 Graph Convolutional Network(GCN)?
深度学习笔记5:池化层的实现
max-pooling和mean-pooling卷积层与池化层 卷积向下取整,池化向上取整。
例题:(Here)
- 输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为?
答案:97。
公式:
卷积层1:
(input_size - kernel_size + 2*padding)/stride + 1=(200-5+2*1)/2+1 $$\longrightarrow$$floor(99.5)=99池化层:
(99-3)/1+1 $$\longrightarrow$$ceil(97)=97卷积层2:
(97-3+2*1)/1+1 $$\longrightarrow$$floor(97)=97全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为
1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽。以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:
“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”
经过此卷积操作后可得输出为1x1x4096。
如需再次叠加一个2048的FC,则可设定参数为“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能。
微调(fine tuning)是深度学习领域最常用的迁移学习技术。
1x1卷积一般只改变输出通道数(channels),而不改变输出的宽度和高度。

卷积:一个函数经过区间镜像翻转和平移后与另一个函数的乘积的积分。
Source: http://fourier.eng.hmc.edu/e161/lectures/convolution/index.html
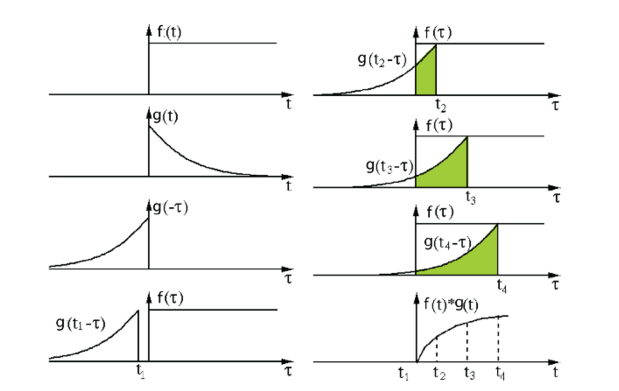
在深度学习中,卷积中的过滤函数是不经过翻转的。
深度卷积:一个函数f经过平移后与另一个函数g的乘积的积分。深度卷积即互关联(Cross-correlation)。
过滤函数:函数 g 称为一个过滤函数。
执行卷积的目的就是从输入中提取有用的特征。
真子空间:一个空间若真包含于另一个空间,那么它就是另一个空间的子空间。
张量空间:一个空间如果是以张量(多维离散立方体)的形式定义的,就叫张量空间。
一张图像就是张量空间(矩阵空间)上的一个点,也就是张量。
窗口:一个真子空间称为原空间的一个窗口。
通道(channel):如果过滤函数g在张量空间中有一个窗口,在这个窗口外g恒零,那么称这个窗口叫g的通道。
卷积核(kernel):给定张量空间,一个存在通道的过滤函数g,称为张量空间上的一个卷积核。
卷积核本身就是张量。一般而言,定义卷积核同时就应该明确指定所使用的通道。
在深度学习中,卷积就是元素级别( element-wise) 的乘法和加法。
对于一张具有单通道(单卷积核)的图像,卷积过程如上图所示,过滤函数是一个组成部分为
[[0, 1, 2], [2, 2, 0], [0, 1, 2]]的 3 x 3 矩阵,它滑动穿过整个输入。在每一个位置,它都执行了元素级别的乘法和加法,而每个滑过的位置都得出一个数字,最终的输出就是一个 3 x 3 矩阵。(注意:在这个示例中,卷积步长=1;填充=0。)
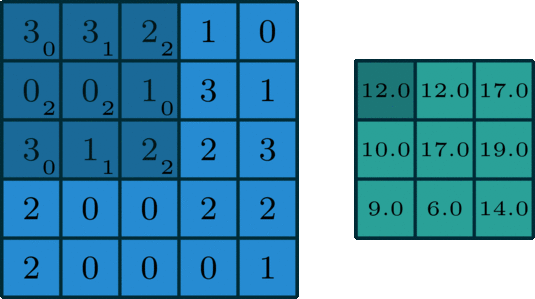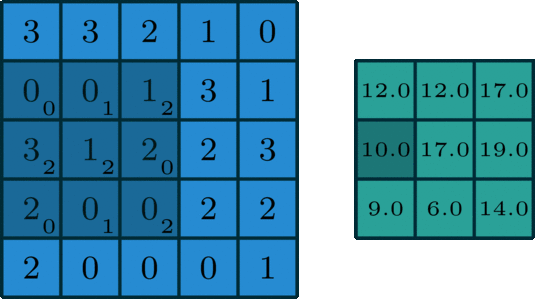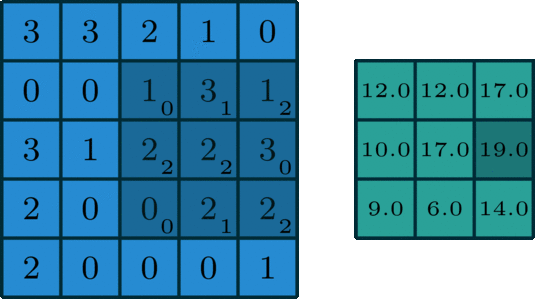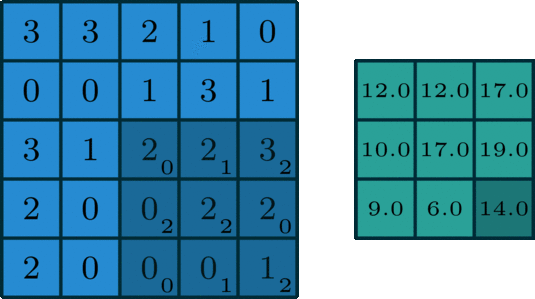
滑动卷积:过滤函数不变,卷积核遍历所有相同规模的窗口,上图所示的过程就是滑动卷积。
如果按照一定步长迭代,并非遍历的话,也可以有类似的讨论。叫做广义滑动卷积。
覆盖卷积:如果张量上定义若干个卷积核,这些卷积核的通道构成张量空间的一个覆盖),则这些卷积核可覆盖卷积。
滑动卷积是覆盖卷积的特例。
插一句,有限覆盖定理。(虽然没什么关系~)
卷积映射(卷积层):一个张量被若干卷积核覆盖卷积,获得新张量,则称为卷积映射。
卷积映射函数即过滤器(filter)。有时过滤器也指若干卷积核堆积形成的张量。
一个卷积映射就对应一个卷积层。
通过卷积映射,原张量被嵌入到一个相对规模更小的张量空间中。
卷积核可以不一样哦。不一定等效于滑动卷积了。
卷积核大小(Kernel size):卷积核的窗口的大小。
卷积步长(Stride):卷积核滑动通过图像的步长。
填充(Padding):填充定义如何处理图像的边界。
- 空填充(将输入边界周围的填充设置为 0,
padding='same')

- 不填充(映射后张量变小,
padding='valid')
Tensorflow中padding的两种类型SAME和VALID
A guide to convolution arithmetic for deep learning (《深度学习的卷积算法指南》,详细介绍各种卷积核操作)
多通道卷积:如果覆盖卷积中任意一个卷积核都构成滑动卷积,那么称为多通道卷积。
下面是一个3个卷积核的滑动卷积(RGB位图)。一个图像可以是多层的,滑动卷积只需要在某一层上滑动。
Source: https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1

之后,这 3 个通道都合并到一起(元素级别的加法)组成了一个大小为
3 x 3 x 1的单通道。
这个通道是输入层(5 x 5 x 3 矩阵)使用了过滤器(3 x 3 x 3矩阵)后得到的结果。

更广义的如下图:(紫色部分的长度就是通道数目,全部合并)

这其实就是高维卷积核(过滤器)。
如果通道不发生合并:(
Din=Dout)

以及推广的高维卷积核,窗口可以在多个维上滑动:(
Din>Dout)

在执行计算昂贵的 3 x 3 卷积和 5 x 5 卷积前,往往会使用 1 x 1 卷积来减少计算量。
1 x 1 卷积最初是在 Network-in-network 的论文中被提出的,之后在谷歌的 Inception 论文中被大量使用。

转置卷积:卷积映射的对应的张量膨胀的卷积称为一个转置卷积。
如果转置卷积映射存在逆映射,则称为逆卷积。


转置卷积的原理如下图所示:


转置的含义来自上述原理中的矩阵的转置。而逆来自逆映射。
空洞卷积(Dilated Convolution):在卷积核部分之间插入空间让卷积核膨胀。即扩张卷积。

类似海绵。本质上是在不增加额外的计算成本的情况下增加感受野。
《使用深度卷积网络和全连接 CRF 做语义图像分割》(Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs,https://arxiv.org/abs/1412.7062)
《通过空洞卷积做多规模的上下文聚合》(Multi-scale context aggregation by dilated convolutions,https://arxiv.org/abs/1511.07122)
还有可分离卷积、扁平化卷积、分组卷积等。(详见Here)
VGG引述
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》(PDF)中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:
- 在分类任务上排名第二,在定位任务上排名第一。

VGG分类
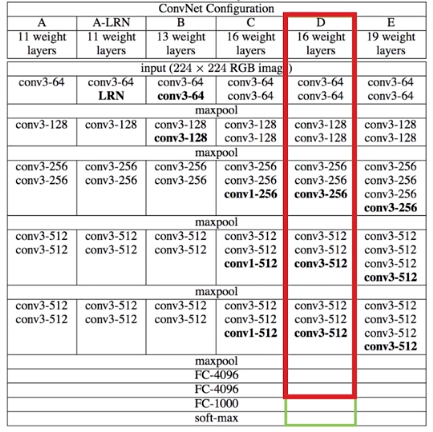
VGG中根据卷积核大小和卷积层数目的不同,可分为A,A-LRN,B,C,D,E共6个配置(ConvNet Configuration),其中以D,E两种配置较为常用,分别称为VGG16和VGG19。

对VGG16进行具体分析发现,
VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用
conv3-XXX表示- 3个全连接层(Fully connected Layer),分别用
FC-XXXX表示- 5个池化层(Pool layer),分别用
maxpool表示其中,卷积层和全连接层具有权重系数,因此也被称为
权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
VGG的优点
VGG16的突出特点是简单,体现在:
- 卷积层均采用相同的卷积核参数:
- 卷积层均表示为
conv3-XXX,其中conv3说明该卷积层采用的卷积核的尺寸(kernel size)是3,即宽(width)和高(height)均为3,3*3是很小的卷积核尺寸,结合其它参数(步幅stride=1,填充方式padding=same),这样就能够使得每一个卷积层(张量)与前一层(张量)保持相同的宽和高。XXX代表卷积层的通道数。
- 卷积层均表示为
- 池化层均采用相同的池化核参数池化层的参数均为2×2,步幅
stride=2,max的池化方式,这样就能够使得每一个池化层(张量)的宽和高是前一层(张量)的1/2。 - 模型是由若干卷积层和池化层堆叠(stack)的方式构成,比较容易形成较深的网络结构(在2014年,16层已经被认为很深了)。
综合上述分析,可以概括VGG的优点为: Small filters, Deeper networks
VGG的缺点
训练时间过长,调参难度大。
存储容量大,不利于部署。(存储VGG16权重值文件的大小为500多MB)
块(Block)
VGG16的卷积层和池化层可以划分为不同的块(Block),从前到后依次编号为Block1~block5。
- 每一个块内包含若干卷积层和一个池化层。
- 同一块内,卷积层的通道(channel)数是相同的。
block3: 3个卷积层,卷积核尺寸为3*3,通道数都是256

随着层数的增加:
- 卷积通道数翻倍:64→128→256→512(到512不再增加了)
- 张量尺寸减半:224→ 112→ 56→28→ 14→ 7(池化层)
VGG参数
VGG参数包括卷积核参数和全连接层参数。两者都需要学习得到。
- 卷积核参数
- 对于第一层卷积,由于输入图的通道数是3(RGB),网络必须学习大小为3×3,通道数为3的的卷积核,这样的卷积核有64个,因此总共有(3×3 × 3)× 64 = 1728个参数。
- 全连接层参数
- =
前一层节点数×本层的节点数。
- =
- 最大池化层没有参数
FeiFei Li在CS231的课件中给出了整个网络的全部参数(138 357 544 个参数)的计算过程(不考虑偏置),如下图所示,图中红色是计算所需存储容量的部分;蓝色是计算权重参数数量的部分:(Lecture 9: CNN Architectures)

VGG16构建代码
1 | from keras.models import Sequential |
输出
1 | Using TensorFlow backend. |
可以看到参数是138,357,544个,基本可以认为构建无误。
VGG19构建代码
不妨再模拟一个常用的VGG19。
VGG19只是在第3、4、5块(Block)各增加一个卷积层。
1 | from keras.models import Sequential |
输出
1 | Using TensorFlow backend. |
QA
提交作业时,所有文件都需要上传吗?还是只需要上传修改后的.py文件?
未回答。(Remain)
是的。
代码中卷积核只指定了窗口的大小3*3,那么卷积核的过滤函数是怎么确定的呢?
参数通过通过反向传播训练的。Check!图像是RGB三位(层)的,为什么不是指定3个卷积核形成过滤器(滑动窗口),而是64、128……?步长是keras自行确定的吗?指定的卷积核个数是在图像上默认均匀分布吗?而且64个3*3窗口根本没法覆盖224x224的图像啊。。orz
64代表卷积核的个数,步长自己设,keras默认步长应该是1。卷积通过滑动覆盖整个图片。
RGB只有3个通道,64个卷积核不应该对应64个通道吗,怎么滑动?
64个卷积核是指单个图像被64个过滤器分别过滤了。64通道是处理后的通道,224 224 3处理后可以变成224 224 64。
“处理”具体对应的是哪一步?什么操作?
处理代表卷积层;通过卷积层之后通道数就变了。
Conv2D的filters和strides参数不会互相冲突吗?它们指定的对象有什么区别?
filters代表卷积核个数,stride代表步长,没有冲突。Check!多个卷积层堆积到一起究竟有多大意义?我看padding都是从输入图像最边缘的一层像素开始的,就算迭代3次,外部的padding也只能向内传播3个像素深度,除了增加算力以外有什么好处吗?我难道不可以直接设置一个具有新的过滤[复合函数]的卷积核来完成这样的工作吗?
多个卷积核,每个卷积核的参数都是不一样的,相当于你说的复合函数。
有什么好处?如果相当于复合函数为什么不直接用复合函数?
是因为神经网络其实本身就是通过不断训练,梯度下降,达到某一个复杂函数的效果。(Remain)(深层次)训练效果更好。
我看VGG模型的C配置里有conv1-512,能讲讲1 1卷积核的作用吗?这里的图像也就三层,为什么要反复用1 1卷积呢?类似于一个像素级的激活函数吗?(那么还要ReLU干啥呢。。)另外1 1为什么要放在33卷积核的[后面]?
1 * 1卷积核用于改变通道个数,比如从12 12 256变成12 12 512就可以用1 * 1卷积层。
那不同配置卷积层数不同不影响通道吗?Check!池化层到底干了个啥?为啥每次池化了以后通道数翻倍呢?
池化层用于下采样。通道变多是为了组合不同的特征。
我想问的是通道为什么会变多?(不是问“为了什么而变多”orrrrz)
因为卷积核个数多了,处理代表卷积层;通过卷积层之后通道数就变了。
卷积可以改变通道数???池化也可以改变通道数?Check!我还是不太理解卷积核数大于通道数是如何过滤的?神奇的操作??
嗯嗯,一个卷积核就可以把之前的所有通道都进行一遍卷积操作,输出为n m 1,x个卷积层就是n m x,所以x跟之前的层有多少通道没关系。
Task2 特征提取

迁移学习

代码
1 | from keras.models import model_from_json |
Task3 数据生成
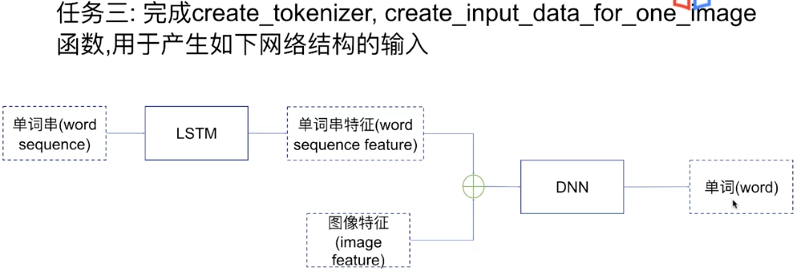
代码
1 |
Task4 训练网络
代码
1 |
Task5 模型评估
代码
1 |