这个知识智能讲座主要讲了抽象化知识对机器学习领域应用的新进展。
本知识智能讲座,我并没有去现场orz(
睡过头了233)。
References
视频链接:
清华大学知识智能研究中心发布会(上)
https://v.qq.com/x/page/b0832d17jiw.html
清华大学知识智能研究中心发布会(下)
http://v.qq.com/x/page/b0832d17jiw.html
讲座新闻:News
AMiner报告下载地址:
2019年第一期《人工智能之数据挖掘》
2019年第二期《人工智能之知识图谱》
知识表示学习工具包OpenKE: https://github.com/thunlp/OpenKE
神经网络关系抽取工具包OpenNER: https://github.com/thunlp/OpenNER
神经网络关系抽取工具包OpenNRE: https://github.com/thunlp/OpenNRE
Few Shot Learning关系抽取数据集FewRel: https://github.com/thunlp/FewRel
XLore: https://xlore.org
基于义原的开放语言知识库 OPEN HowNet: https://openhownet.thunlp.org/
相关论文
Must-read papers on neural relation extraction (NRE):https://github.com/thunlp/NREPapers
Must-read papers on network representation learning (NRL) / network embedding (NE):https://github.com/thunlp/NRLPapers
Must-read papers on knowledge representation learning (KRL) / knowledge embedding (KE):https://github.com/thunlp/KRLPapers
Jing Zhang, Jie Tang, Cong Ma, Hanghang Tong, Yu Jing, Juanzi Li:
Panther: Fast Top-k Similarity Search on Large Networks. KDD 2015(数亿节点的)大规模网络,给定节点,快速计算与之具有
Topk相似度的节点的随机路径算法。Yang Yang, Yizhou Sun, Jie Tang, Bo Ma, Juan-Zi Li:
Entity Matching across Heterogeneous Sources. KDD 2015异构领域(Source$\rightarrow$Target)的实体匹配概率算法+可解释性(基于主题)。
YixinCao, Lifu Huang, Heng Ji, Xu Chen, Juanzi Li:
Bridging Text and Knowledge by Learning Multi-Prototype Entity Mention Embedding. ACL 2017基于多类型实体模型的数据、知识的链接。(主要解决Ambiguity)
Xin Lv, Lei Hou, Juanzi Li, Zhiyuan Liu:
Differentiating Concepts and Instances for Knowledge Graph Embedding. EMNLP 2018知识图谱嵌流算法。
Yilin Niu, Ruobing Xie, Zhiyuan Liu, Maosong Sun:
Improved Word Representation Learning with Sememes. ACL 2017根据义原提升单词的表示学习性能。
Zhigang Wang, Juan-Zi Li:
Text-Enhanced Representation Learning for Knowledge Graph. IJCAI 2016知识图谱:利用文本增强的表示学习。
Fanchao Qi, Yankai Lin, Maosong Sun, Hao Zhu, Ruobing Xie, Zhiyuan Liu:
Cross-lingual Lexical Sememe Prediction. EMNLP 2018基于义原的多语言推广预测。
Yihong Gu, Jun Yan, Hao Zhu, Zhiyuan Liu, Ruobing Xie, Maosong Sun, Fen Lin, Leyu Lin:
Language Modeling with Sparse Product of Sememe Experts. EMNLP 2018基于义原的稀疏语言模型。
简介
刘知远。
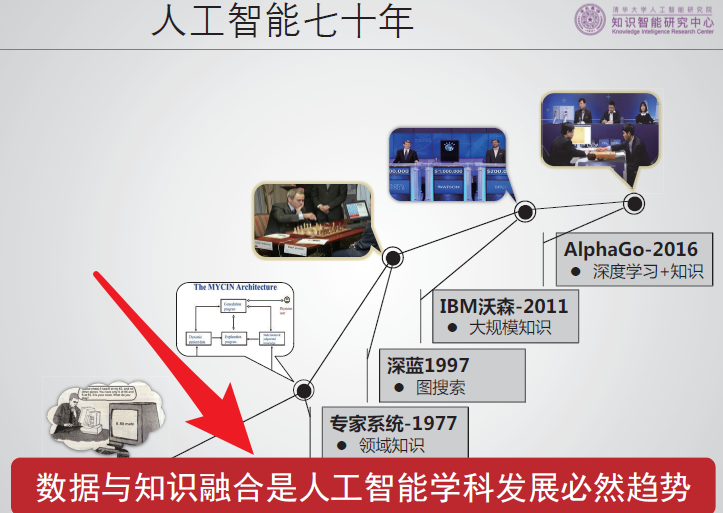
新一代人工智能应该是可信,安全,可解释、鲁棒的,要把知识加入。
知识驱动+数据驱动。
后人工智能时代?
张钹院士:国内对于知识表示、知识推理和知识库的建立重视还是非常不够,ijcai论文中该类研究国内较少,科学研究必须多样化!
人工智能:数据+知识。(形象+抽象)
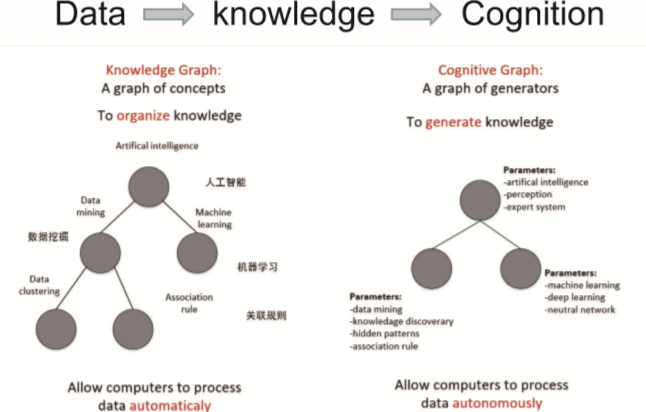
语言翻译到语言是简单的,但没有常识的话很难获得句子的真意。

国际构建大量的知识图谱。(我国的研究却较少)
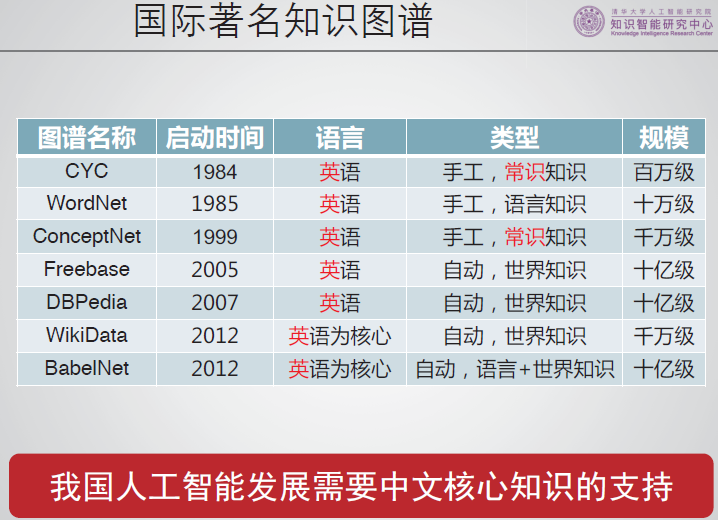
清华知识智能有三个相关方面的研究方向。

介绍了多个相关的平台。

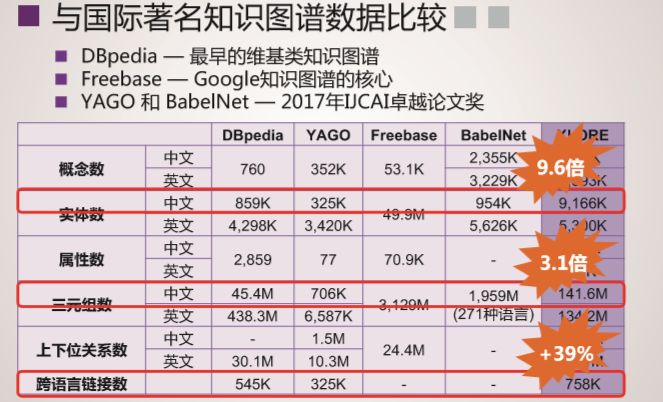
XLORE是中英文知识规模平衡的大规模跨语言百科知识图谱,该图谱通过融合维基百科和百度百科,并对百科知识进行结构化和跨语言链接构建而成。该图谱以结构化形式描述客观世界中的概念、实例、属性及其丰富语义关系。XLORE目前包含约247万概念、44.6万属性/关系、1628万实例和260万跨语言链接。XLORE作为世界知识图谱,将为包括搜索引擎、智能问答等人工智能应用提供有力支撑。

知网HowNet秉承还原论思想,认为词义概念可以用更小的语义单位来描述、这种语义单位被称为“义原”(Sememe),是最基本的、不易于再分割的意义的最小单位。
研究发现,HowNet通过统一的义原标注体系直接精准刻画语义信息,一方面能够突破词汇屏障,深入了解词汇背后丰富语义信息;另一方面每个义原含义明确固定,可被直接作为语义标签融入机器学习模型,使自然语言处理深度学习模型具有更好的鲁棒性可解释性。

2019年hownet与清华共同推出OpenHowNet

知网核心数据的开源。
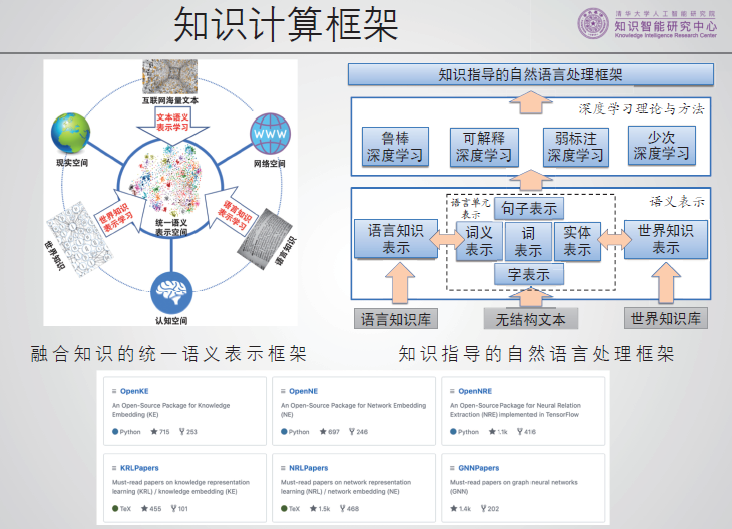
融合语言知识的语言表示学习。
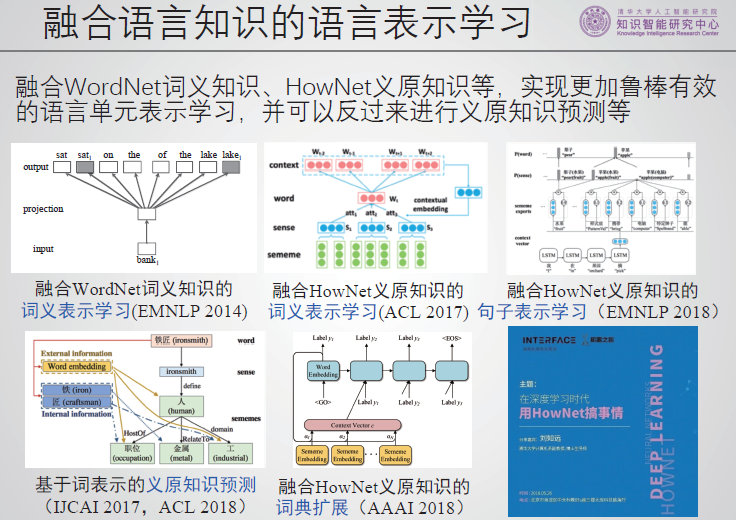
考虑复杂结构的世界知识表示学习。

知识计算工具包。

知网HowNet
提出问题


发展

难点:(义原)
根据语言学家的定义,义原是最小的不可分的语义单位。有的语言学家认为,包括词在内的所有概念的语义都可使用一个有限的义原集合去表示。而义原是比较隐含的语义单位,所以人们需要利用已经构建好的义原知识库才能够获取一个词所对应的义原。
知网对词进行了更细粒度的义原标注,因而被广泛用于各项自然语言处理的任务中。


知网的义原集,30年来几乎是稳定的。(词汇量增加)
义原集比较像计算机中的RISC集。
HowNet不等于NLP,更像一个数据资源库。
OpenHowNet
项目地址:https://openhownet.thunlp.org/
相关研究:https://openhownet.thunlp.org/publication


百科XLORE
背景意义
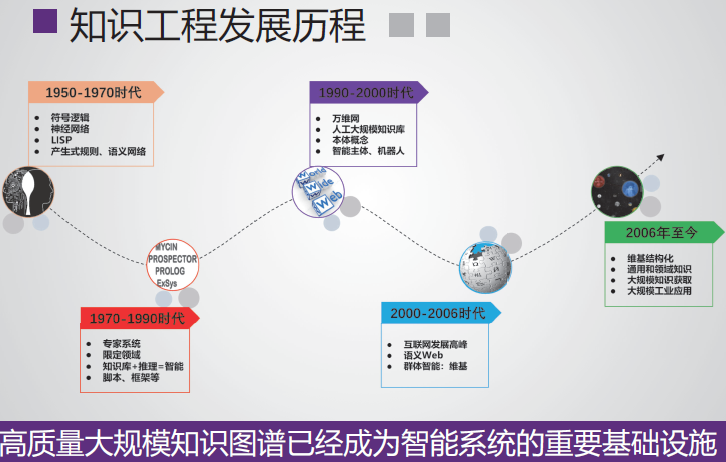
在线百科知识资源:

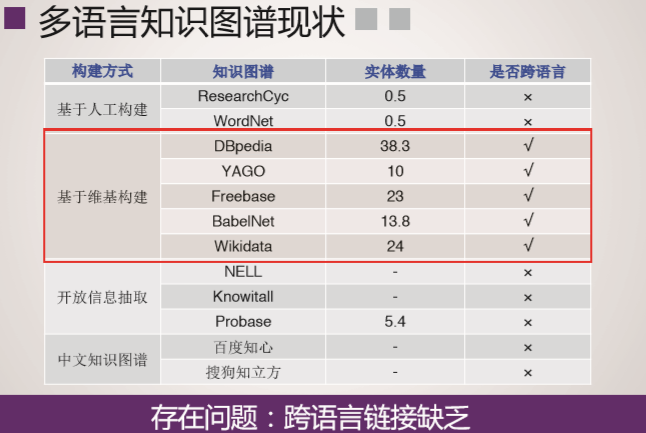
多语言知识图谱现状:
概念与实体。

技术特色
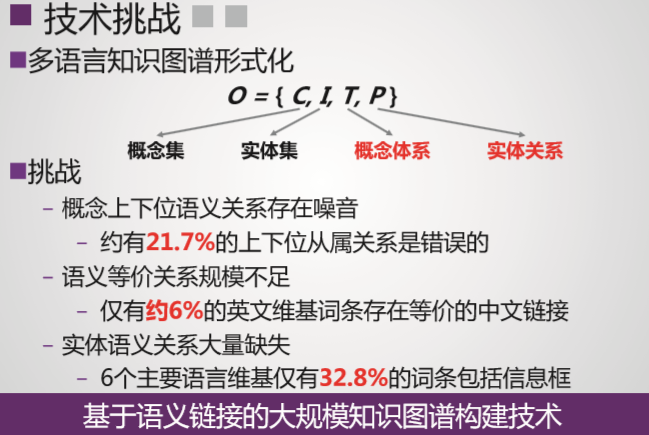

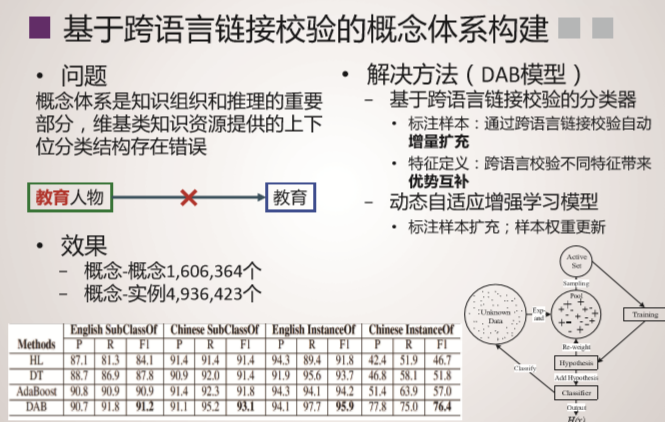

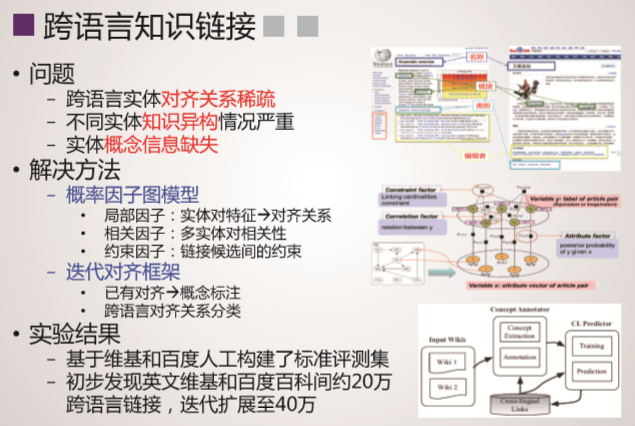
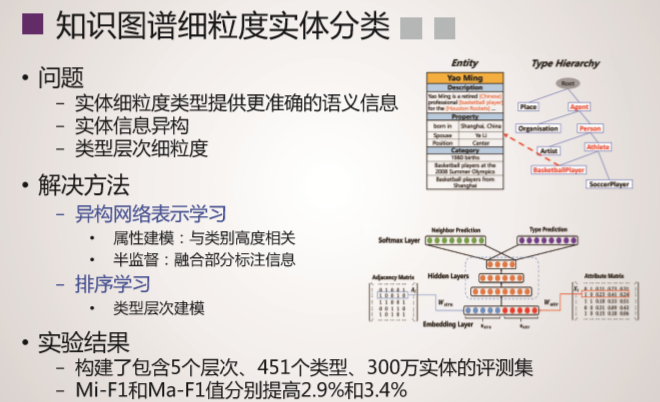
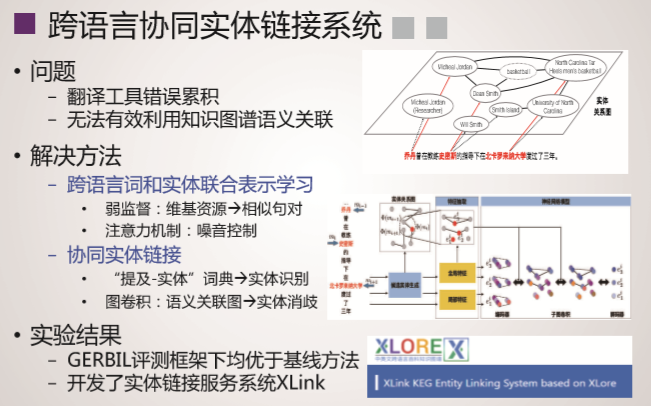
系统概况

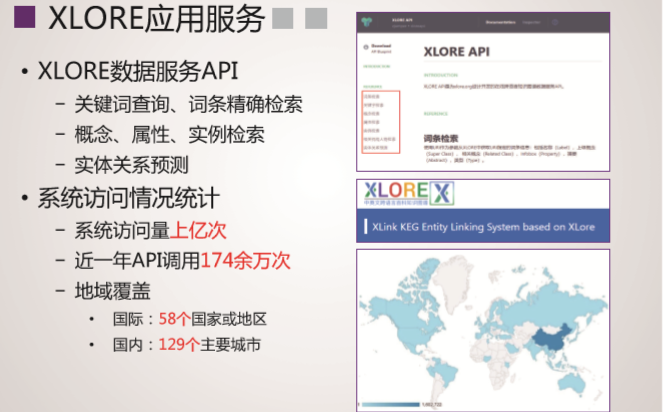
数据发布
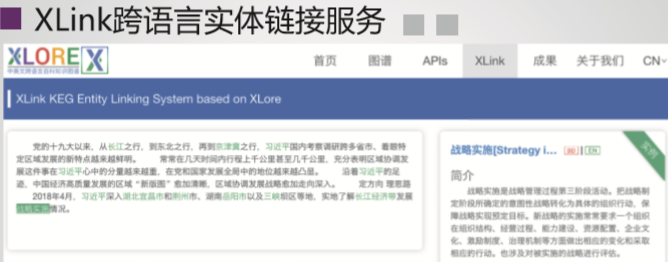

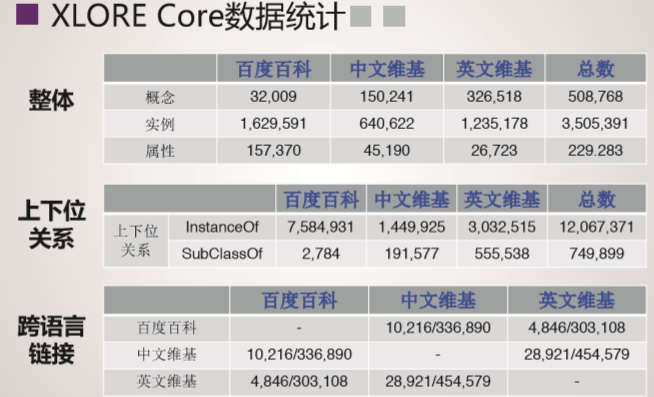
总结与展望

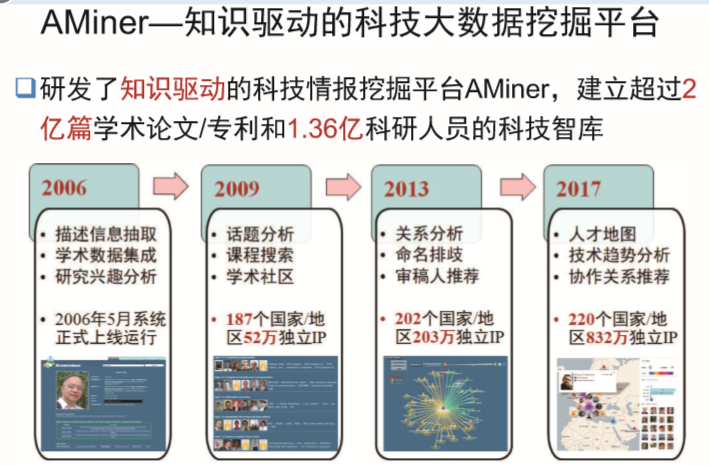
科研AMiner
General
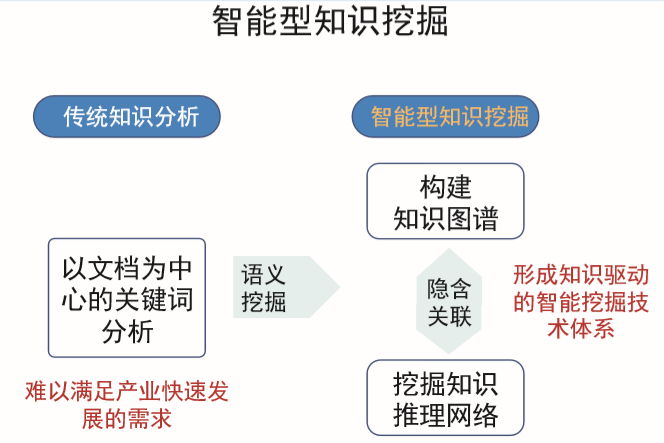

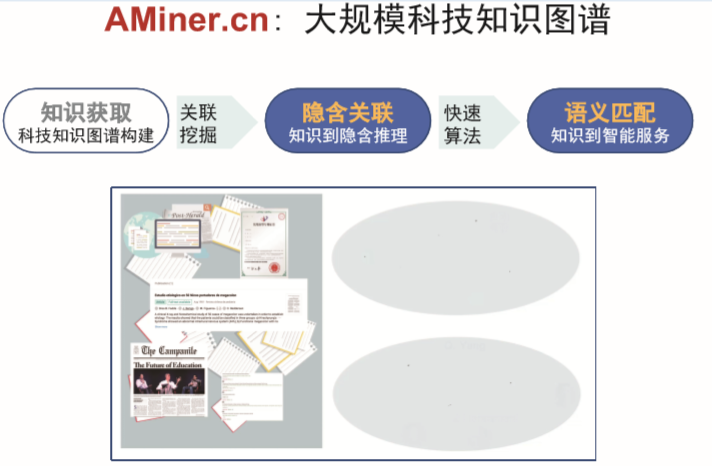
分析深层关系(挖掘),推理(算法),匹配(推荐)。

Future
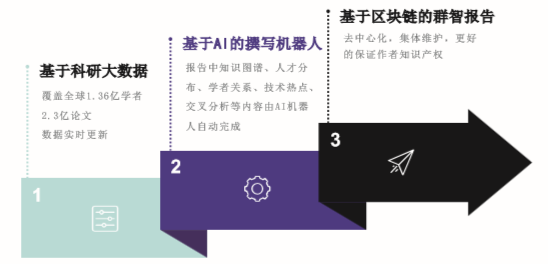
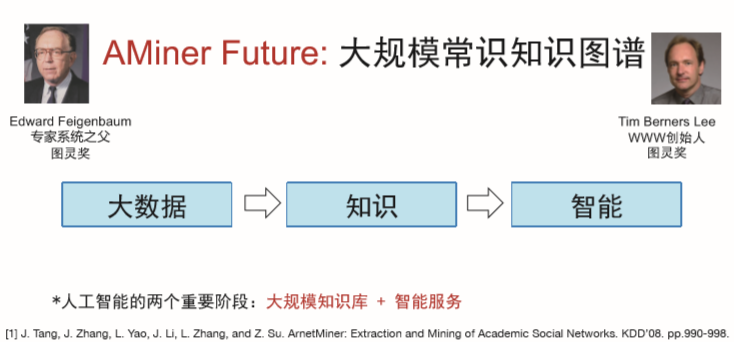
快速构建知识图谱,建立科研对象的框架。设计框架与图谱的交互系统。
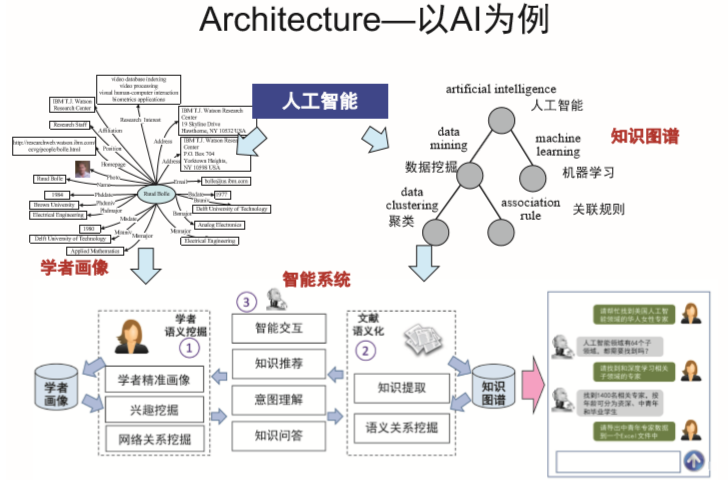

常识知识图谱到大规模知识图谱。异构网络的协调问题。
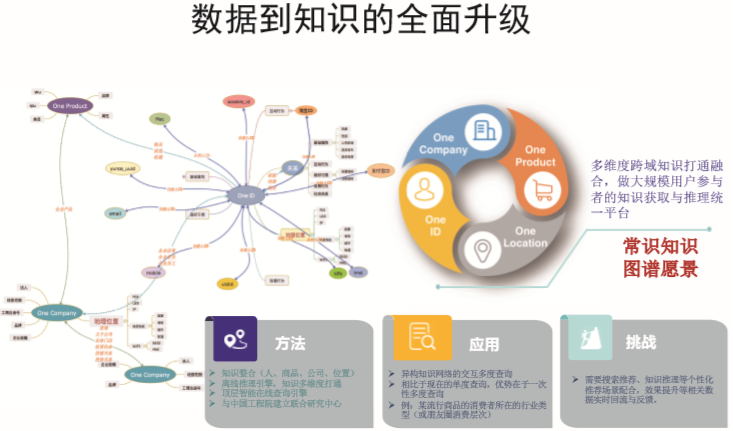
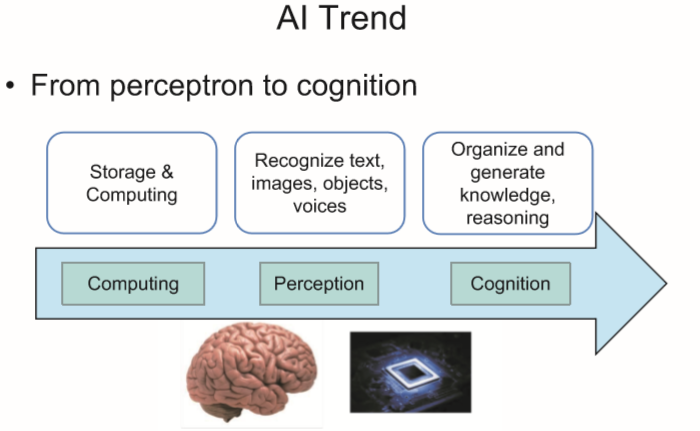
从感知到认知。
节点:概念——模型。
总结:概念是逻辑结构,模型是存储结构。(并不必存储概念,只需要存储概念的编码信息,然后在需要输出时进行翻译就行了)