Introduction Python中的Pyspider是用于开发网络爬虫——网上大数据收集工具的一个框架。
收集数据为了下一步大数据处理(机器学习)做准备。
初等pyspider操作指南 原文是在之前学习Pyspider的过程中撰写的,参考了大量资料,这里统一谢过大佬们~
# 阅读之前假设已经完成以下内容:
以上扩展知识均可以在本文的Reference部分找到。
def Checking(Your_current_stauts):
If 前三项内容已经全部完成:
return 合理的假设 = 你可以写一个简单的、能运行的爬虫 了。
elif 全部已完成:
return 合理的假设 = 本操作指南的大部分内容你已能够独自实现 。
else :
return Excuse me???
实现一个最简单的爬虫 详情见《Python3網絡爬蟲實戰》Youtube视频的第20集,这里只作简单叙述。(我还是讲一下吧233~~)
再贴一下第20集的网址:
https://www.youtube.com/watch?v=nHYHdZqDib0&index=20&list=PLlOGeDt-ISLoiX7OyMHYT9t0DOUhL-pxi&t=0s
没看的快去看!~~
好的,咳咳,进入正题!
我们要实现的核心功能 如下:
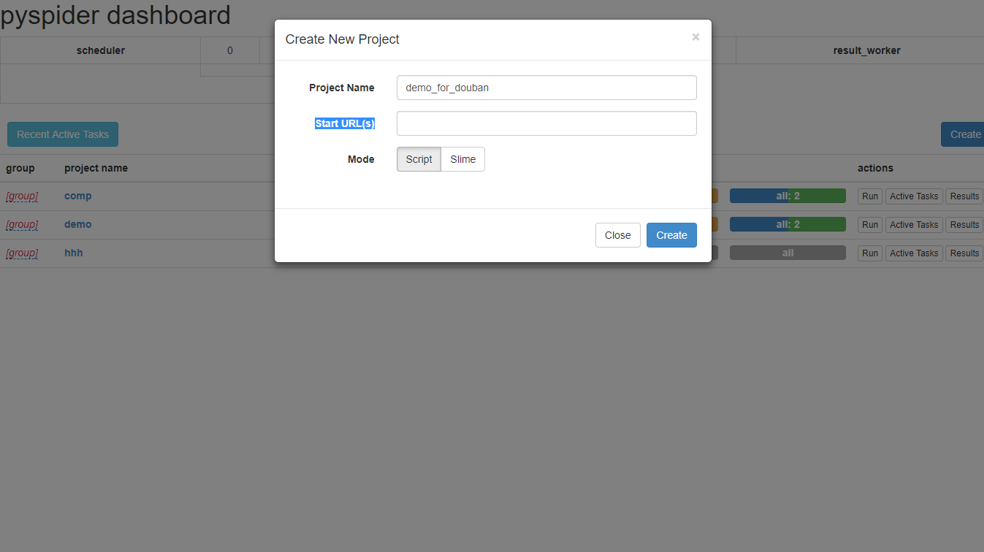
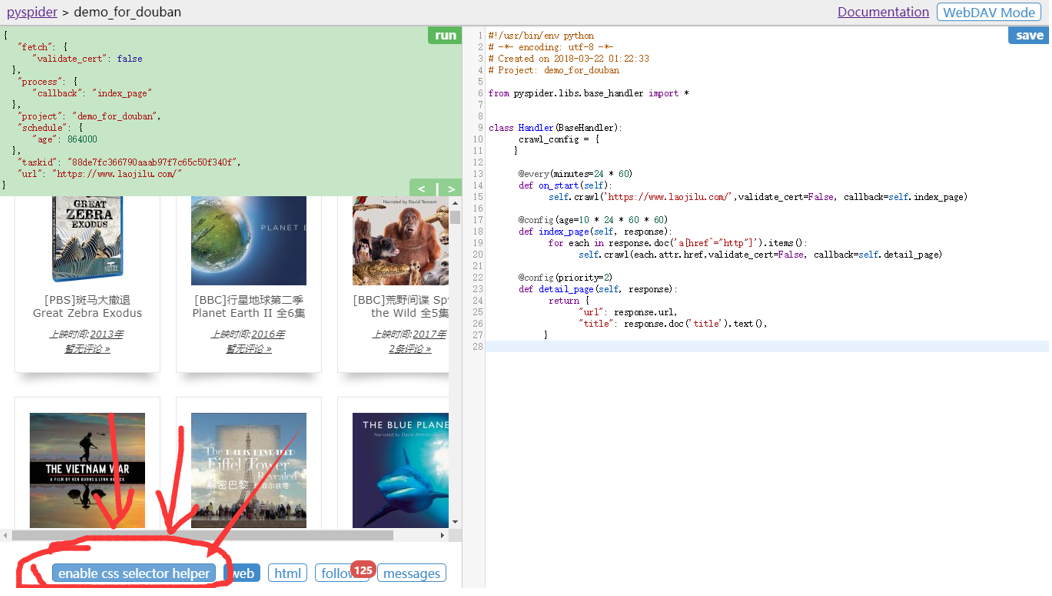
搭建框架 首先创建一个项目:“demo_for_douban”,Start URL(s)这一栏可填可不填,因为它的本质是用来提供信息,好为我们自动创建一个模板。
点击Create。
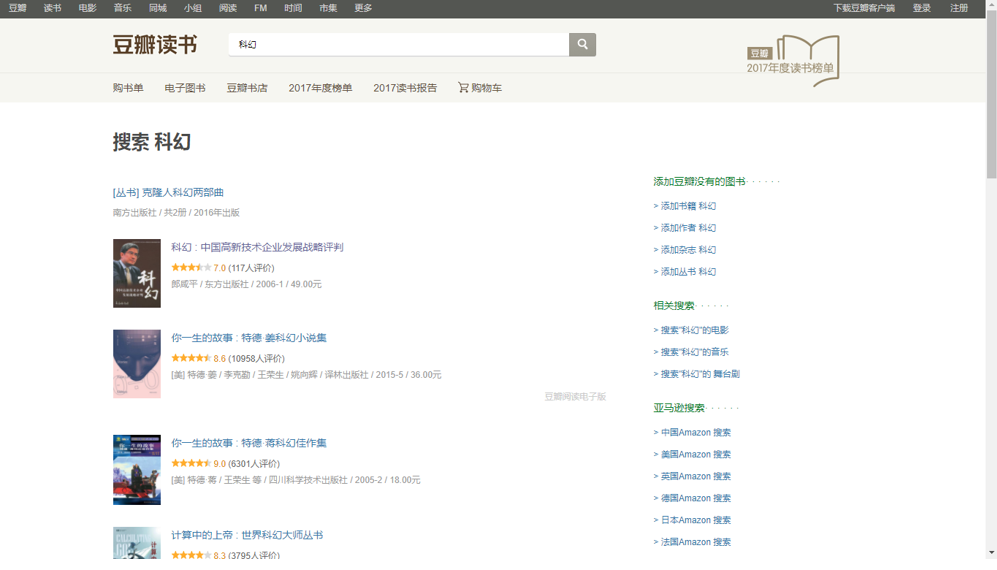
接着,打开豆瓣网,进入豆瓣读书,搜索“科幻”。
这便是我们要爬取的索引页。
网址如下:
https://book.douban.com/subject_search?search_text=%E7%A7%91%E5%B9%BB&cat=1001
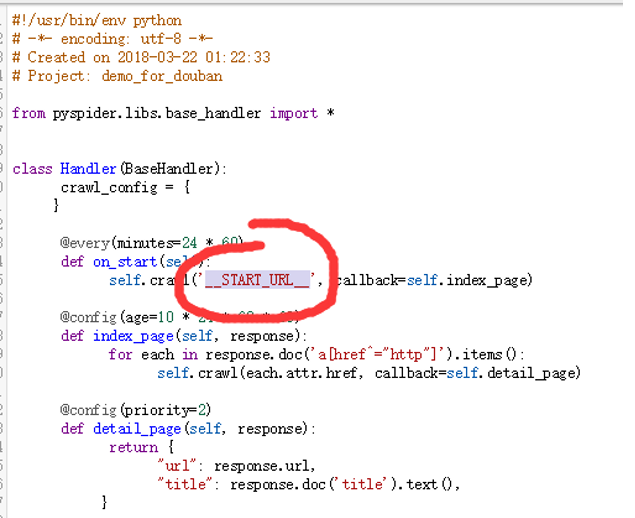
将START_URL 改成咱们对应要爬取的网页。(如果Start URL(s)这一栏之前在create的时候已经填了,那么这里会初始化为你填的那个网址哦。)
单击save。
从on_start这个初始化的函数,通过:
self.crawl('https://book.douban.com/subject_search?search_text=%E7%A7%91%E5%B9%BB&cat=1001', callback=self.index_page)这个方法,咱们crawl了咱刚刚填进去的网址,然后把这个网址的内容送(回调)到index_page 这个函数里面进行进一步解析。
看到没有!index_page的结构跟on_start函数的结构几乎一毛一样嘛!就是多了一行:
for each in response.doc(‘a[href^=”http”]’).items() :
看上去好像是明明白白的英文,不就是对每一个(for each)在……中(in)我去执行下一行的操作——而这个“……”里面的内容不就是response.doc(‘a[href^=”http”]’).items() 那一串吗?也是response.doc(‘a[href^=”http”]’) 这个东西的items() (项)嘛。
回顾一下咱们的任务:
根据之前crawl的写法,这里可以猜测,each.attr.href应该代表一个网址,这个“.attr.href”后缀肯定就是每一个item()的网址了。它又callback了detail_page,这不是内容页面的意思吗?那就是说,item()的网址肯定是一个内容页面的形式了。
这里重点 讲一下response.doc(‘a[href^=”http”]’) 的功能,即获取网页上的某个元素。不懂没关系,你只需要知道它是从网页上获取某些东西 就可以了。
咱们要获取的内容页面detail_page是什么呢?如下图中所示。
我们把每个电影的页面记作内容页面,现在我们尝试获取内容页面的网址。
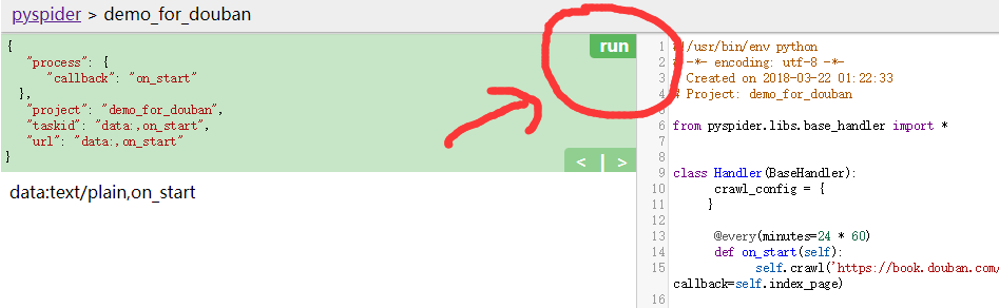
点击Run。
点击follows。
点击三角形,执行下一步,
你会惊喜的发现——
hhh
报错了。。。。
是的。
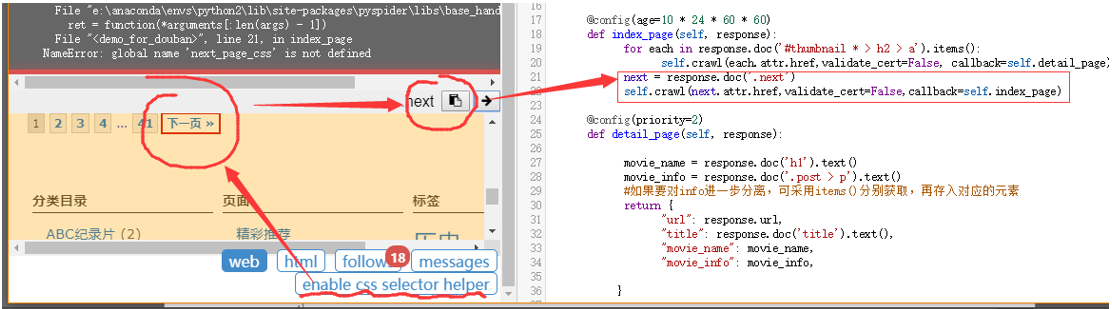
这个错误是由于咱们爬取的网址是https开头而不是http,这时,crawl函数里面必须加入一个参数,validate_cert=False 。
于是正确的姿势应该是下面这样~
Index_page里面的crawl也要记得添加validate_cert=False 哦。
好了,我们再跑一遍。
仍然会出现问题哦!!!
这里面的原因,其实跟豆瓣这个网址设置了反爬虫机制有关,如果想要爬取豆瓣的信息,就需要更高级的手段,咱目前还达不到,因此只好换个网站~
(讲这里是让大家提前意识到反爬虫以及反反爬虫的技术的重要性 ,今后有很多的网站可能有反爬虫的机制,越有名越难爬,大家要有心理准备~)
PS:我会告诉你我懒得改?2333333(逃~
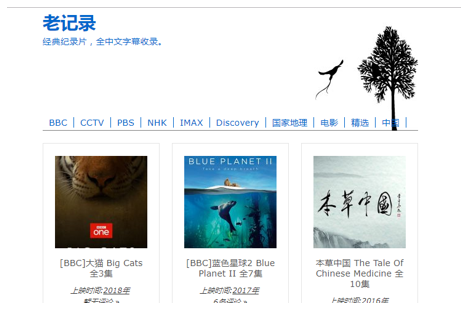
爬取内容 我们换成老记录网,这是一个很好的纪录片的网站哦!安利一下。。。
把网址改成:https://www.laojilu.com/
再次运行,出现detail_page了,出现了125个网址,这些网址有些可能跟我们的需求无关,你看第一个,就是老记录的主页,这个没什么用嘛。我们要爬取的是下面这样的内容网页。
我们点击Web。如下图。
可以看到老记录的主页哦。
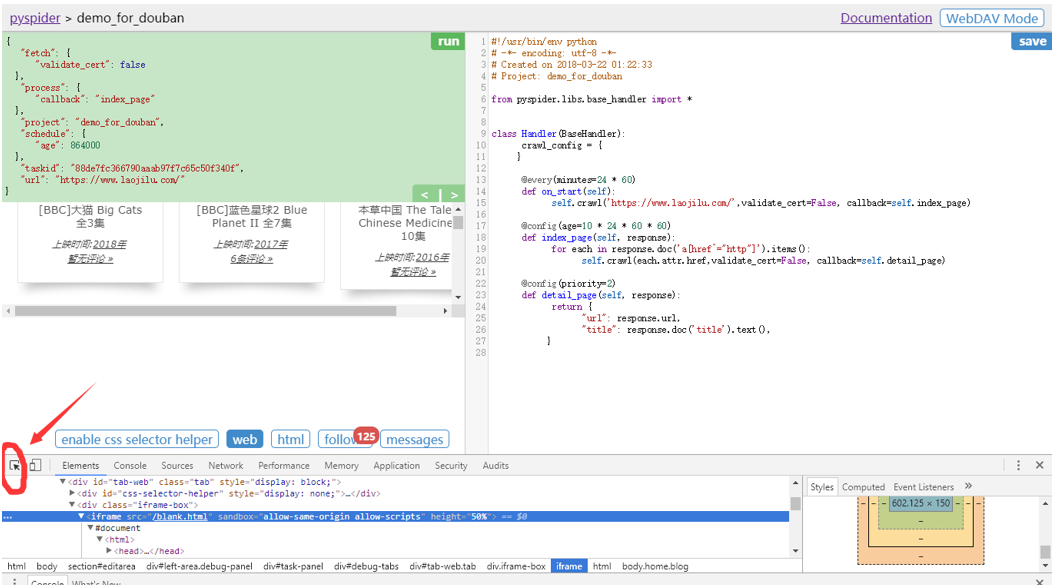
是不是有点窄?没关系,咱们调节一下,Chrome中按F12,启动查看元素,点击红圈中的按钮。
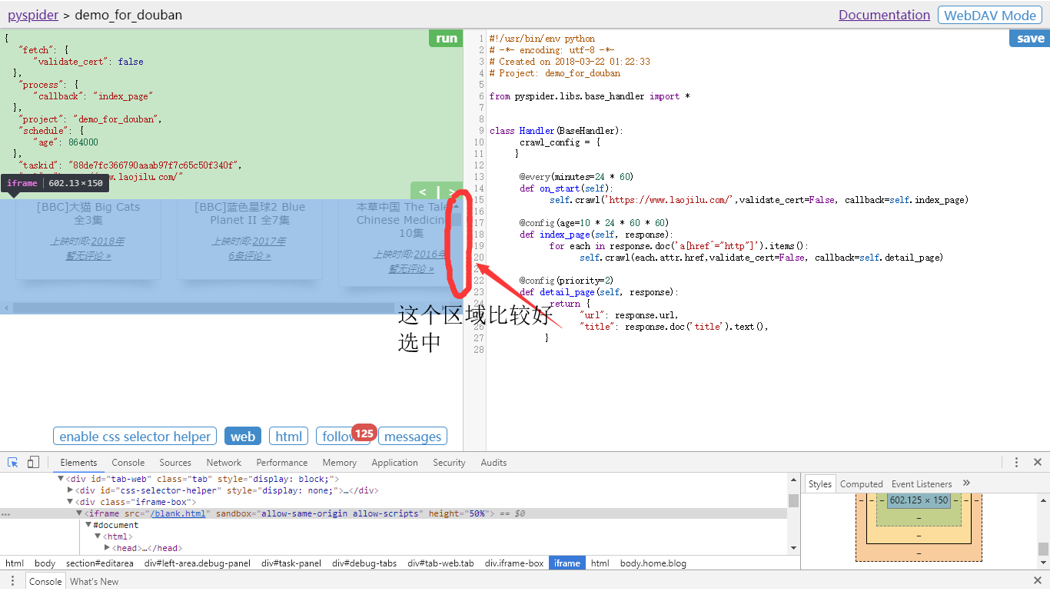
选中视窗。
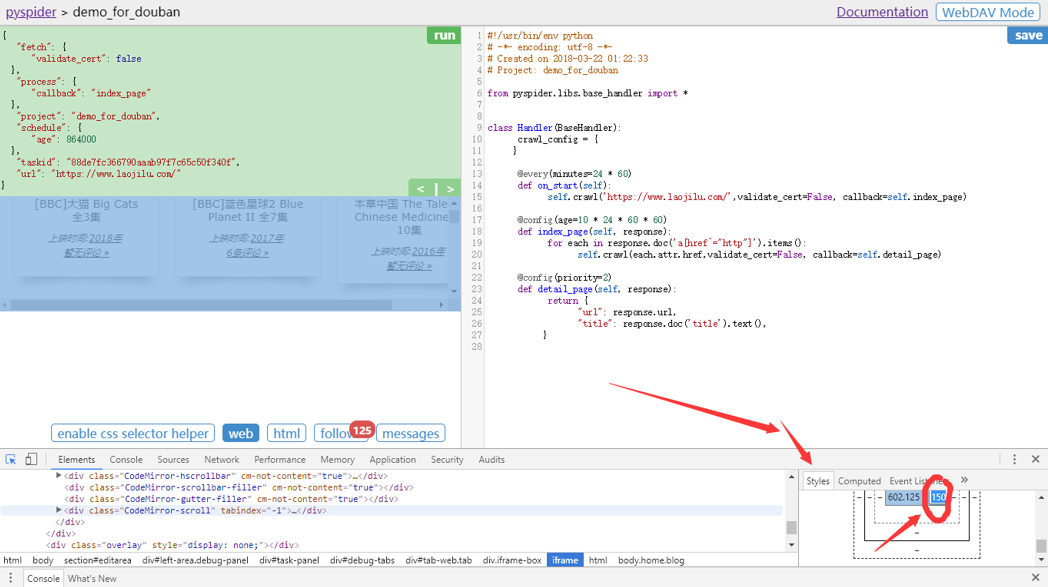
更改Style。双击修改宽度150->450。F11关闭元素查看。好看多了!
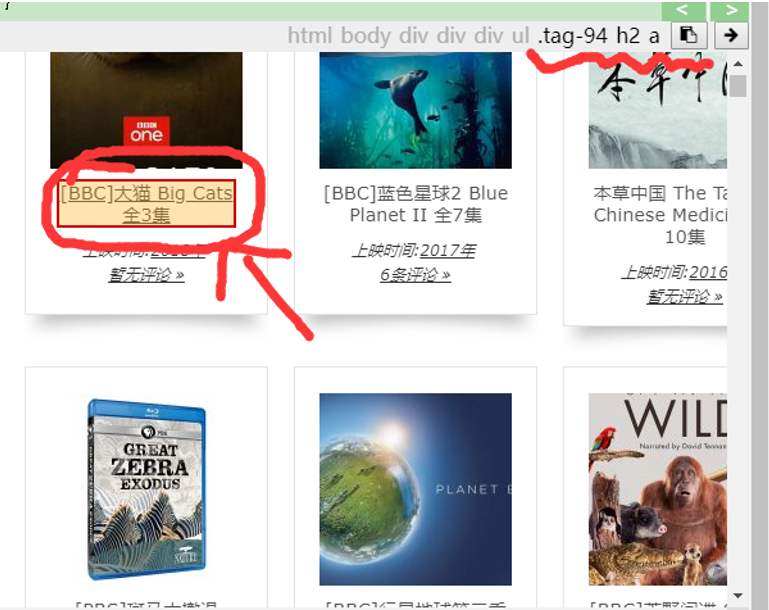
点击enable css选择器按钮。
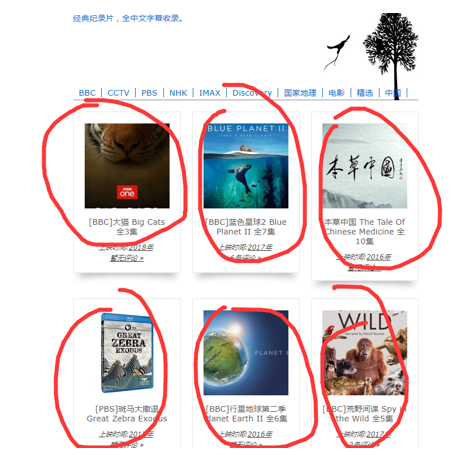
选中图中所示的链接,进行CSS选择。可以看到右上角出现了初具雏形的表达式。
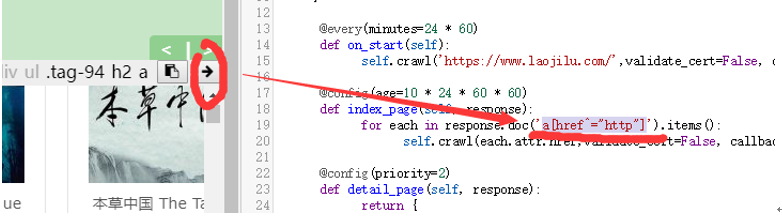
我们点击右上角第一个按钮,复制这个表达式。第二个按钮用来将其插入代码当中。选中index_page里面的a[href^=”http”]表达式,用我们新选择的表达式替换。
点击save。重新run。
只剩下一个网页了!!!这可不妙,咱们筛选得好像太过分了。我们重新选择一遍。
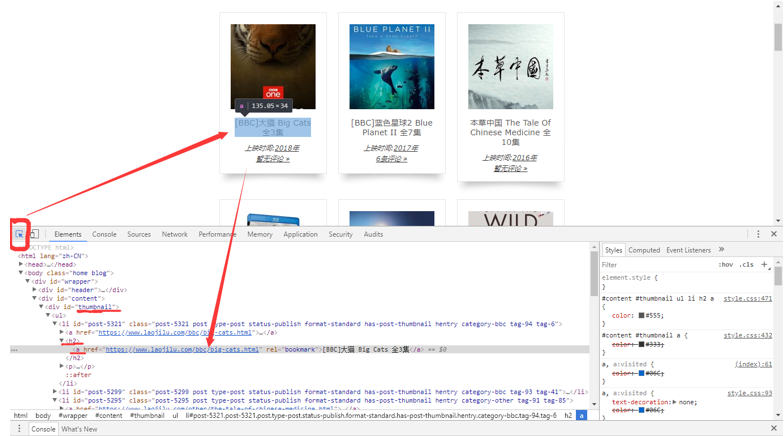
我们按F11查看一下老记录网主页的Html,并用红圈中的按钮来选择刚刚的元素查看一下它的结构。
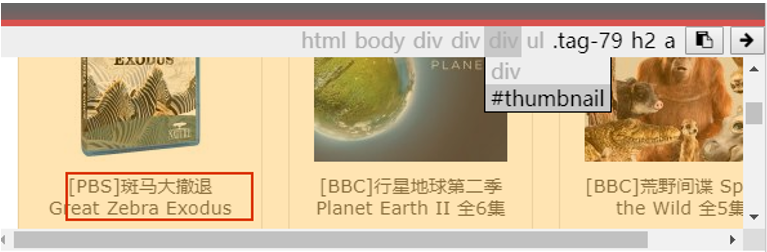
我们看到结构是这样的,thumbnail类下面,这里面有很多的内容页面,每个保存在h2 > a这样的结构里面。
我们尝试重新做一下CSS表达式。把thumbnail添加进去,点击.tag-79删去这个不必要的说明。
可以看到,这次页面都被选中了。我们把新的表达式覆盖到代码里面。
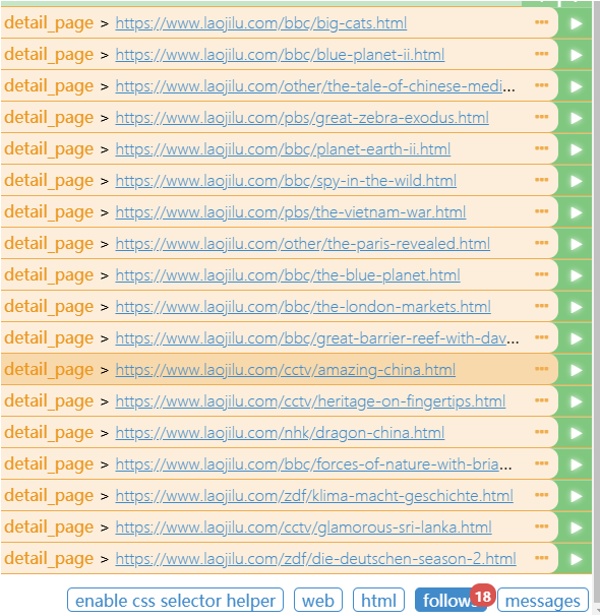
Save,run,看下效果。效果不错哟~~
随便点一个绿色三角。这里我们点第一个做个示范。
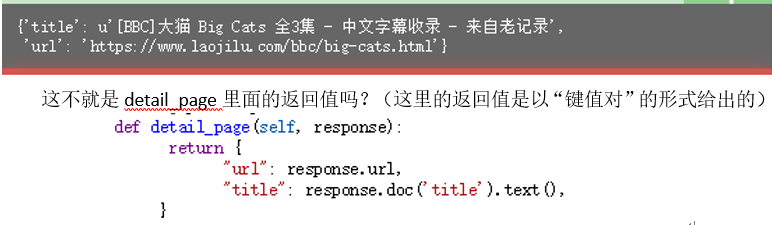
看!有结果了!分别是title,url的信息。
这不就是detail_page里面的返回值吗?(这里的返回值是以“键值对”的形式给出的)
这就给了为我们一个提示:如果,想要获取更多的信息,可能需要把获得的信息写到return里面。
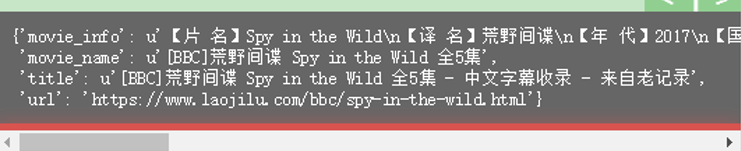
如果想要更多的信息要怎么做呢?
照样,重复类似的步骤就行了。我就不详细写了。下面贴出代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from pyspider.libs.base_handler import *class Handler (BaseHandler ): crawl_config = { } @every(minutes=24 * 60 ) def on_start (self ): self.crawl('https://www.laojilu.com/' ,validate_cert=False , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc('#thumbnail * > h2 > a' ).items(): self.crawl(each.attr.href,validate_cert=False , callback=self.detail_page) @config(priority=2 ) def detail_page (self, response ): movie_name = response.doc('h1' ).text() movie_info = response.doc('.post > p' ).text() return { "url" : response.url, "title" : response.doc('title' ).text(), "movie_name" : movie_name, "movie_info" : movie_info, }
以及运行的抓取结果:(抓取图片的技术比较复杂,可以看demo中的实现方法)
结果展示 再回顾一下咱们最开始的目的~~
咱们已经实现了前后的内容和结果,可是翻页操作还没实现呢!这可要命,没有翻页操作的话,爬完这一页,下一页不就不能爬了?
这里要设计一个index_page的循环。我获取这一页索引的内容页之后,能够转到下一页索引,继续获取新的内容页。
添加两行代码,获取下一页的链接。
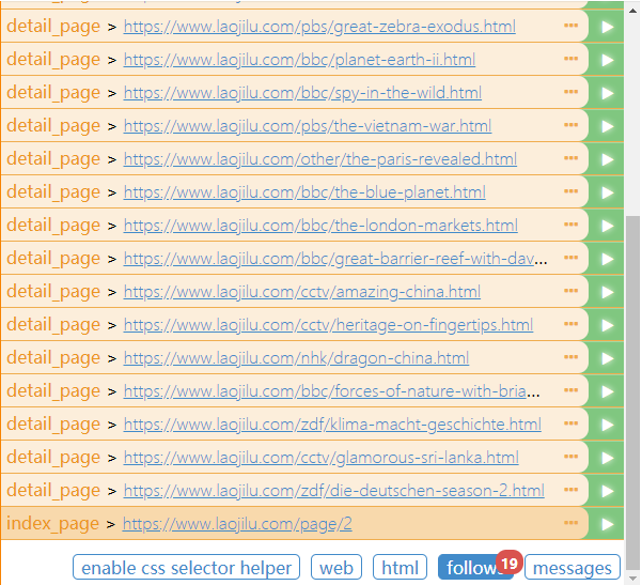
再run一遍,发现follows从18个分支,变成了19个,多了个index_page。这便实现了翻页操作。
给出一个总的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from pyspider.libs.base_handler import *class Handler (BaseHandler ): crawl_config = { } @every(minutes=24 * 60 ) def on_start (self ): self.crawl('https://www.laojilu.com/' ,validate_cert=False , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc('#thumbnail * > h2 > a' ).items(): self.crawl(each.attr.href,validate_cert=False , callback=self.detail_page) next = response.doc('.next' ) self.crawl(next .attr.href,validate_cert=False ,callback=self.index_page) @config(priority=2 ) def detail_page (self, response ): movie_name = response.doc('h1' ).text() movie_info = response.doc('.post > p' ).text() return { "url" : response.url, "title" : response.doc('title' ).text(), "movie_name" : movie_name, "movie_info" : movie_info, }
当然,我们最终的目的是要将爬取的结果保存到本地嘛。
我们借助demo里面改写的on_result方法,Tool工具类,以及一系列的库和附加的初始化定义(比如定义图片存储路径的DIR_PATH),就能很方便地实现了!这里就不再作更具体的描述了,留给你练练手吧~
CSS选择器的简单回顾 注意:以下内容是基于你“至少已经看过《Python3網絡爬蟲實戰》Youtube视频的第20集”。
什么是CSS选择器 在pyspider的WebUI上,可以看到五大功能:
按重要程度分别是:
Follows,用于单步调试【可在本指南的如何DEBUG的常用方法中找到更详细的描述】Web,网页,在这里运行到某一步,可查看对应的页面(pyspider的本质是自动地浏览网页,并把网页的内容有选择性地下载下来)Enable css selector helper,CSS选择器。通常与网页的html结合起来使用,这样获得的CSS表达式往往更准确
使用方法:见《Python3網絡爬蟲實戰》Youtube视频的第20集
Message,消息(队列),不常用Html,不常用
抓取合适的CSS 通常通过pyspider的WebUI提供的CSS选择器,我们已经可以很方便地抓取大部分的网页内容。但是仍然有少量的内容可能出现一些问题,这时咱们可以借助Chrome自带的网页元素查看器,进行更细致准确的分析。
比较常出现的情况是:表达式含义不唯一 。比如抓取content,可能一个content对应了好多个元素a,那么这时就要用到正则表达式了。
最简单的正则表达式 咱们一般会用的正则表达式(我目前遇到的)有且仅有一种。
就是 .xxx > xxx > xxx[“XYZ=ABC”] 的形式。
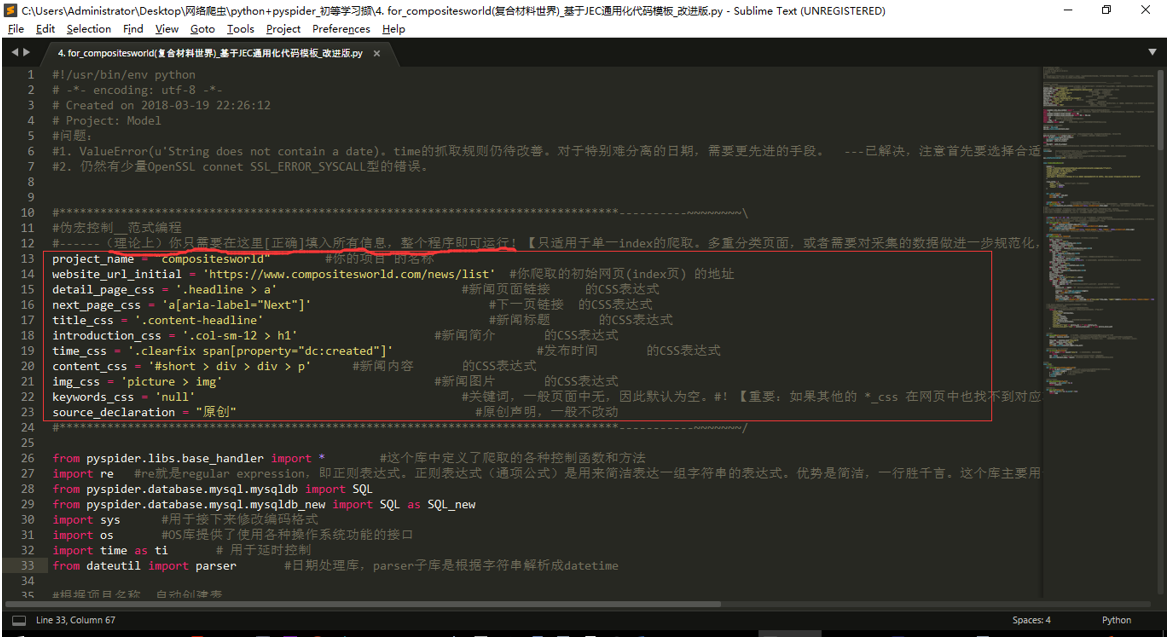
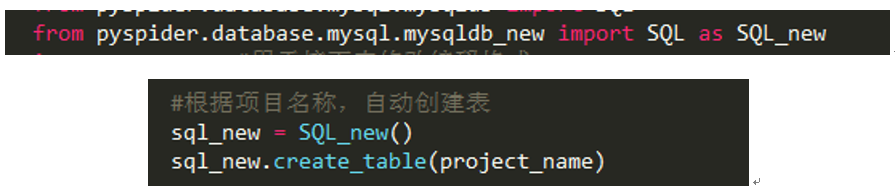
在我之前给大家的“4. forcompositesworld(复合材料世界) 基于JEC通用化代码模板_改进版”里,有下面一行代码:
这就是典型的应用。大家可以按照之前的方法查看一下对应的网页元素,弄清楚为什么这么做。【提示:使表达式的含义唯一 】
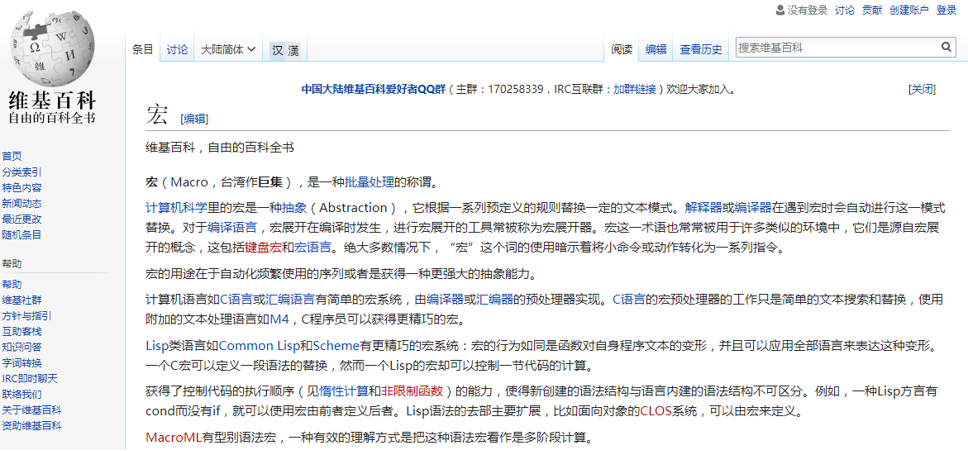
结构化、伪宏控制 伪宏控制 学过C语言的你,可能还记得C语言中有一种功能:宏定义。
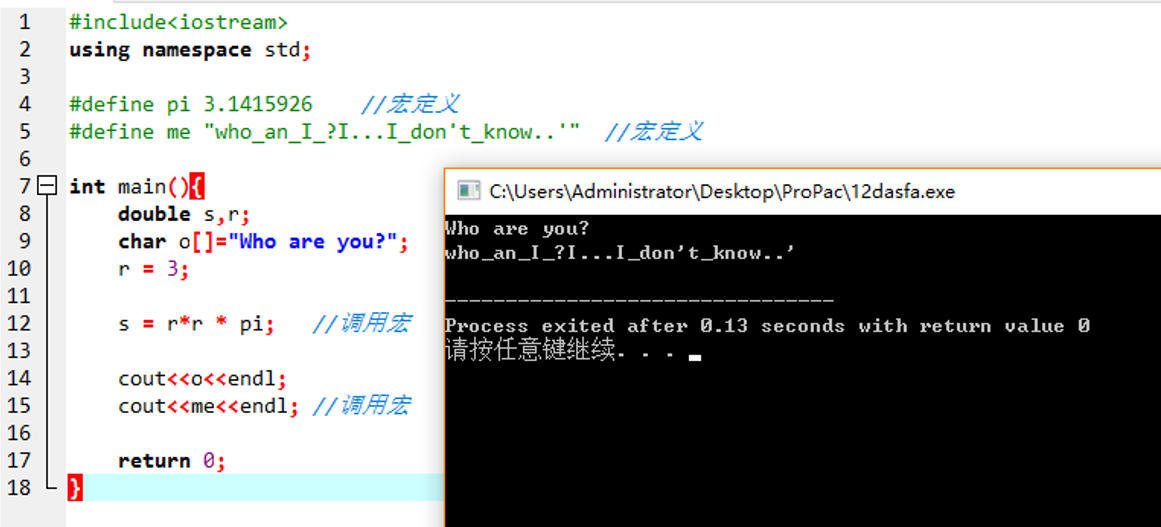
C++中宏定义能够实现类似下面这个示例代码的功能:
可以看到,预先定义的宏可以在接下来的整个程序的任何地方,只要写它的名字就行了。该也非常方便,因为你只用改宏pi,整个程序的pi就能随之而变。
尽管python中没有严格的宏的功能,但我们通过预先把需要调节的参数统一命名赋值,放置到程序的头部,还是可以实现的。这样,咱们的代码就能实现结构化了!
对于同样一种结构的网页,我们使用同一套代码的输入模板就能很方便地修改对应参数,快速编程了。
范式编程 范式就是典型的意思。咱们可以通过一个比较具有代表性的网站的爬取框架,进行范式化。但这个框架的使用一定具有一些条件,这些要在代码中写明。
接下来咱们就能动手实现范式化的编程了。
效果如图。
具体过程我就不详细解释了,如果前面的理解没有问题,这里应该不难。你也可以尝试动手实现自己的一个范式哦~
封装与自动化 自动化创建子目录 细心的你可能已经发现:咱们理论上虽然可以在WebUI/dashboard上一次建立很多个爬虫程序,但是——所有的图片好像都保存在了同一个路径之下???What?还有这种操作?那我保存的图片管理起来岂不是非常混乱……
于是可能会有这样的想法……
如果能够在子目录里面,按照我建的project的名字创建一个专属于这个project的子文件夹,那么张三的文件放到张三的文件夹里,李四的文件放到李四的文件夹里,管理起来岂不是方便多了,而且还很直观。这就是核心的想法。
基于这样的想法,我们对DIR_PATH这个图片保存目录做以下的修改:
(也许你在疑惑我是用了什么主题的IDLE才有这么酷炫的编程界面???那么注意啦,这是Sublime Text 3,非常适合小项目的编程IDE。你可以百度搜索下载哦,只要进行一定的快捷设置,就可以实现在Sublime Text 3进行python程序的运行~具体问度娘~)
整个思路就是:创建一个项目子目录,如果目录不存在。
下面我们尝试创建两个项目。在cmd命令行粘贴以下代码:
1 2 3 4 cd desktop md CraData cd CraData pyspider all
如果成功运行,桌面上将出现一个CraData文件,用于保存爬取的数据。
效果如图:
在WebUI创建两个项目JEC和Comp,分别把
3. 封装for_jeccomposites(JEC) ** 伪宏控制__**范式编程.py
和
4. forcompositesworld(复合材料世界) 基于JEC通用化代码模板_改进版.py
中的代码覆盖到项目的代码中。如下图所示:
回到dashboard,将两个项目的状态都调到running,点击run。
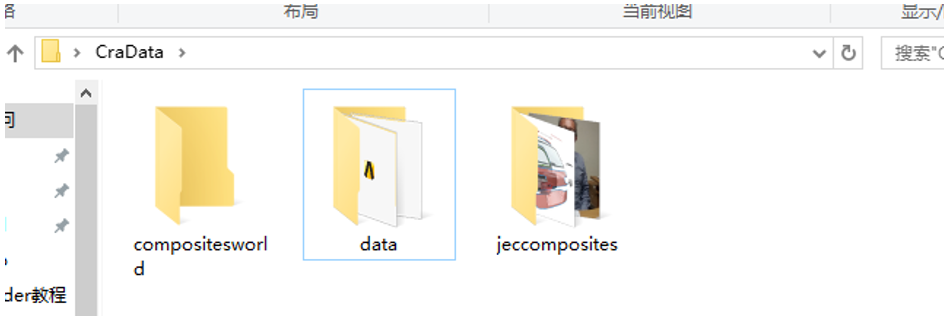
打开图片存放的目录,发现有两个基于project_name生成的子文件夹:
说明运行成功。
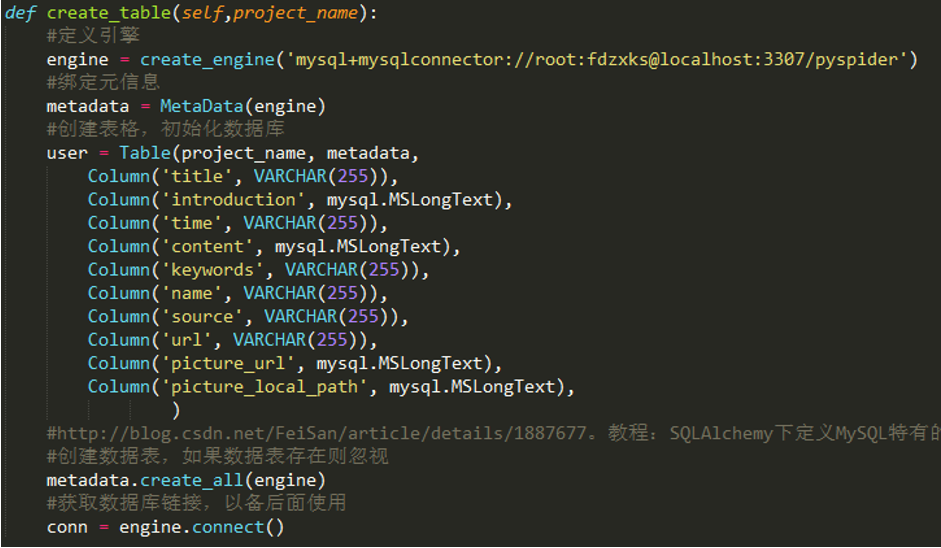
封装——create_table方法的实现 打开mysqldb_new.py文件。
看第三行:
使用该改进方法可能需要安装的库:sqlalchemy,mysql-connector。均可用pip install快速安装。这说明你必须首先安装这两个库,才能使用这个基于mysqldb的改进库。
让我们看看它与mysqldb有什么不同。
可以看到,它的区别主要在于前面引入了三个新库,尾部增加了一个create_table方法。
具体的实现方法就不细讲了,网上可以百度。要使用这个库,把它拷贝到与mysqldb相同的目录下即可。注意需要在
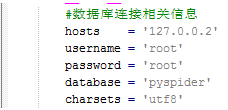
engine = create_engine(‘mysql+mysqlconnector://root:fdzxks@localhost:3307/pyspider’)
这一行进行数据库的连接设置才能正常使用。
下面讲一下怎么调用它。
可以看到,方法里面有两个参数,self,project_name,self是class(类)对象自带的一个默认参数,必须要填,你可以不用管它。project_name参数则比较重要,顾名思义,就是你的项目的名字。如果你已经实现过前面的范式编程,你应该对这个变量名很熟悉。以下是一个调用的实例:
打开之前发过的文件:
\6. testpro 通过调用MySQLnew实现自动创建列表_demo.py
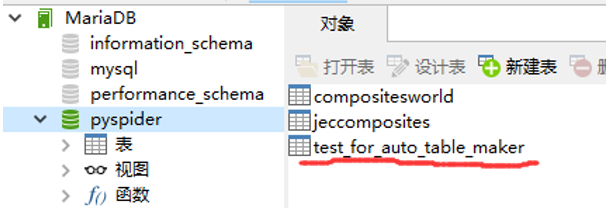
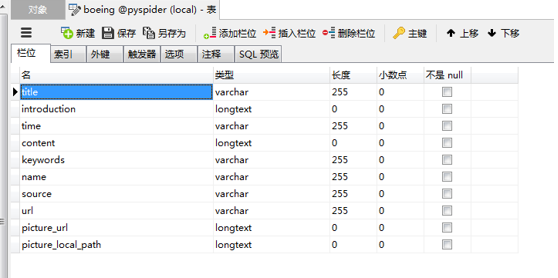
Run一下。打开Navicat,发现有新的表格自动建立了。【必须先保证前面数据库连接参数已设定好】
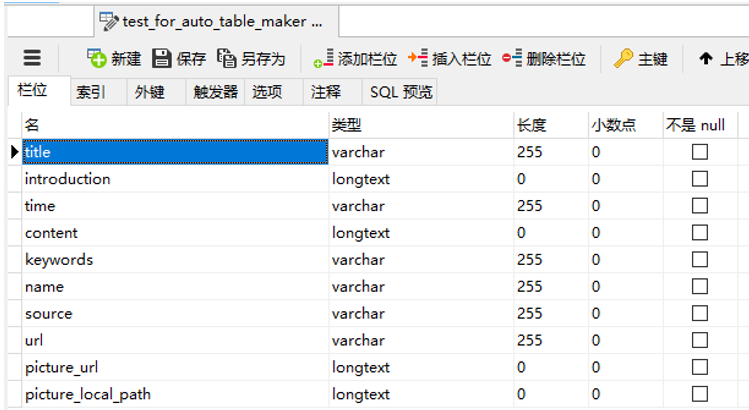
右键选择“设计表”查看表结构。
与咱们需要的表结构一致。运行成功。
PS:test_for_auto_table_maker是一个名字,你可以任意指定/修改。
自动化创建表 首先咱们需要在代码中加入两个部分:
然后就能够自动创建表了。【但你首先要完成之前的步骤哦】
代码重用 聪明的你也许已经发现了,到现在为止,咱们的demo代码里面,还有两大块我没有提到过。它们是:
和
这两个部分,一个用来初始化,一个用来定义工具类,都是咱们可以直接调用的方法,它们的存在,更类似于库,只不过没有封装成一个库用import引进来而已。因此,咱们不用太关注里面具体是如何实现的,你只需要知道它的功能,需要输入什么,能够输出什么,就足够了。而这些,代码中的注释应该能给你一定的启发。如果还有问题,随时百度哦。
如何DEBUG? DEBUG是什么 DEBUG是什么,首先要知道BUG是什么,即“虫子”(虫族??),计算机学中用来指代程序、代码的漏洞。例如,在长达上亿行代码的window操作系统中,漏洞的数量也是非常多的,成千上万。BUG是非常难以彻底避免,对于大型的项目,甚至有相关的指标规定:如,千行代码缺陷率(bug率)。
只要代码是人写的,出错的原因一定在自身。【这里已经默认你已经完成了环境的部署哦,如果环境设置没弄好而出现的问题不属于这里的讨论范围~】那么,就要找找自己的原因了,是否对程序的框架不够清楚就匆忙开始写?是否了解自己代码的功能?是否考虑过可能出现的代码BUG,并作一定的预防措施(“可以理解”的报错)?
假若,木已成舟,生米已经熟饭……DEBUG** ——程序纠错、调试就不可避免了。一般来说,质量越差的源代码,调试起来就越困难,耗费的时间也就越长,BUG更加难以识别,甚至天长地久也不能发现。 提高源代码质量的方法:加注释,结构化,封装化**。
常用方法总结 下面介绍Pyspider的三种常用的DEBUG方法:
l 使用单步调试 打开host:5000页面,pyspider dashboard,进入一个project。
之前我们用的点击绿色小三角来单步执行,就是单步调试。不细讲了。
如果你已经实现了往数据库传输结果,在这个阶段请你先屏蔽掉on_result方法,让结果能直接显示在WebUI网页里面,便于分析结果抓取是否合理。
屏蔽掉on_result方法即在对应代码行最前加注释号(或者直接先删掉该方法,之后再粘贴进来):
l 使用命令行调试 修改项目status到running,点击run。
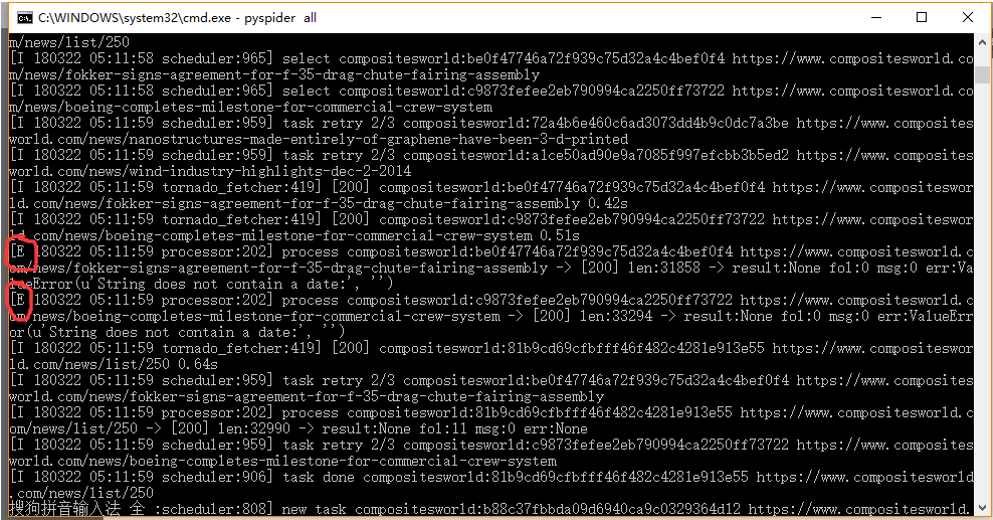
在命令行会发现下面这样的效果:
你会发现最左边的字母,一般只会出现两种状态:“I”和“E”。
“I”我不知道是什么意思,但“E”经我推测应该代表Error的意思。如果你的命令行在运行过程中出现了“E”,请按照给出的错误信息进行调试。
比如我现在就出现了这样的错误:
ValueError(u’String does not contain a date:’, ‘’)
这说明抓取的time里面,有的date(日期)没有抓取下来,字符串是空的,可能需要做一些修改(比如尝试更精确CSS表达式,或者更好地对提取的time做处理)。
一般这里的错误单步调试时理论上也能找到,但由于咱们爬取的页面数量庞大,有些错误还是要依靠命令行来查找。
l 使用前后接口调试 pyspider前接口,对接网页即html;pyspider后接口,对接数据库即mysql。
Html影响获取内容,mysql影响储存信息。
Html的调试,就是选择合适的CSS表达式的过程。
Mysql的调试,查看是否存入数据,数据是否规范等。
已经,对图片保存目录进行查看,是否成功爬取图片。
写在最后 如果time(调试) >> time(写代码),说明源代码质量差,要注意提高代码质量;如果time(写代码)+ time(调试) >> time (average),说明基本功不好,要多练。
强调:写代码一定要高质量,否则调试很麻烦。
这是惨痛的经验~
彩蛋 试试运行以下代码?【先运行pip install turtle】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 from turtle import *import time setup(600 ,800 ,0 ,0 ) speed(0 ) penup() seth(90 ) fd(340 ) seth(0 ) pendown() speed(5 ) begin_fill() fillcolor('red' ) circle(50 ,30 ) for i in range (10 ): fd(1 ) left(10 ) circle(40 ,40 ) for i in range (6 ): fd(1 ) left(3 ) circle(80 ,40 ) for i in range (20 ): fd(0.5 ) left(5 ) circle(80 ,45 ) for i in range (10 ): fd(2 ) left(1 ) circle(80 ,25 ) for i in range (20 ): fd(1 ) left(4 ) circle(50 ,50 ) time.sleep(0.1 ) circle(120 ,55 ) speed(0 ) seth(-90 ) fd(70 ) right(150 ) fd(20 ) left(140 ) circle(140 ,90 ) left(30 ) circle(160 ,100 ) left(130 ) fd(25 ) penup() right(150 ) circle(40 ,80 ) pendown() left(115 ) fd(60 ) penup() left(180 ) fd(60 ) pendown() end_fill() right(120 ) circle(-50 ,50 ) circle(-20 ,90 ) speed(1 ) fd(75 ) speed(0 ) circle(90 ,110 ) penup() left(162 ) fd(185 ) left(170 ) pendown() circle(200 ,10 ) circle(100 ,40 ) circle(-52 ,115 ) left(20 ) circle(100 ,20 ) circle(300 ,20 ) speed(1 ) fd(250 ) penup() speed(0 ) left(180 ) fd(250 ) circle(-300 ,7 ) right(80 ) circle(200 ,5 ) pendown() left(60 ) begin_fill() fillcolor('green' ) circle(-80 ,100 ) right(90 ) fd(10 ) left(20 ) circle(-63 ,127 ) end_fill() penup() left(50 ) fd(20 ) left(180 ) pendown() circle(200 ,25 ) penup() right(150 ) fd(180 ) right(40 ) pendown() begin_fill() fillcolor('green' ) circle(-100 ,80 ) right(150 ) fd(10 ) left(60 ) circle(-80 ,98 ) end_fill() penup() left(60 ) fd(13 ) left(180 ) pendown() speed(1 ) circle(-200 ,23 ) exitonclick()
参考自:https://www.cnblogs.com/wwh8797/p/7739699.html
https://www.zhihu.com/question/21664179
http://www.bugman123.com/index.html
Pyspider环境配置 Pyspider的介绍等请读者自行搜索知悉。
Pyspider的框架搭建过程并不唯一,高级读者可以自行决定。
一些参考资料,可在本文的Reference中找到。
Python2框架
安装python2.7(32位,64位对pyspider支持有问题,相关软件文件夹中直接双击安装即可,注意选择添加环境变量,否则后面需要手动添加环境变量)
Microsoft Visual C++ Compiler for Python 2.7安装(相关软件文件夹中直接双击安装VCForPython27.msi)
安装pyspider
Cmd执行pip install pyspider安装(如果没有pip,可以将C:\Python27;C:\Python27\Scripts两个路径添加到环境变量即可)
安装过程中可能会遇到一些依赖无法安装,需要手动下载安装包。到这个链接网址https://www.lfd.uci.edu/~gohlke/pythonlibs/ ,搜索相应版本的安装包,下载,pip install ** .whl即可
Mysql数据库连接设置
本机装好数据库
将相关软件中mysqldb.py文件拷贝到安装路径C:\Python27\Lib\site-packages\pyspider\database\mysql\下,打开文件修改相关数据库连接参数:
Cmd切换到开发目录下输入pyspider启动,这个目录可以随意见一个,之后在页面写的脚本都会保存在这个目录下。
Anaconda框架 基本操作如上,但Anaconda支持多环境的切换 (比如,py2和py3),更方便。
并且Anaconda会自动安装常用的库 ,对新手更友好。
Demo 下面介绍一个demo
先在mysql建好数据库表:
打开浏览器输入http://localhost:5000/ ,单击create创建爬虫脚本(以爬取美国波音公司媒体网站http://boeing.mediaroom.com/为例 )
输入:
project name:boeing
url:http://boeing.mediaroom.com/
创建之后将以下内容拷贝到右侧代码框中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 from pyspider.libs.base_handler import *import refrom pyspider.database.mysql.mysqldb import SQLimport sys import osimport time as tifrom dateutil import parser reload(sys) sys.setdefaultencoding('utf8' ) DIR_PATH = "./" class Handler (BaseHandler ): headers= { "Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Accept-Encoding" :"gzip, deflate, sdch" , "Accept-Language" :"zh-CN,zh;q=0.8" , "Cache-Control" :"max-age=0" , "Connection" :"keep-alive" , "User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36" } crawl_config = { 'itag' : 'v1.1' , "headers" : headers, "timeout" : 100000 } def __init__ (self ): self.dir_path = DIR_PATH self.tool = Tool() @every(minutes=24 * 60 ) def on_start (self ): self.crawl('http://boeing.mediaroom.com/news-releases-statements' , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc('.archive_nav > a' ).items(): year=each.text() if (year != "Search" ): if (year=="2016" or year=="2015" ): self.crawl(each.attr.href, callback=self.news_page) def news_page (self, response ): for each in response.doc('.item' ).items(): time=each.find('div' ).eq(0 ).text() datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) self.crawl(each.find('div' ).find('a' ).attr.href, save={'time' : time},callback=self.news,connect_timeout = 5000 , timeout = 20000 ) for each_page in response.doc('.table_footer > b > a' ).items(): self.crawl(each_page.attr.href, callback=self.news_page2) def news_page2 (self, response ): for each in response.doc('.item' ).items(): time=each.find('div' ).eq(0 ).text() datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) self.crawl(each.find('div' ).find('a' ).attr.href, save={'time' : time},callback=self.news,connect_timeout = 5000 , timeout = 20000 ) def news (self, response ): time=response.save['time' ] if response.doc('#assets_20295_130083-117_tab_link' ): self.crawl(response.doc('#assets_20295_130083-117_tab_link' ).attr.href,save={'time' : time}, callback=self.detail_page,validate_cert=False ,connect_timeout = 5000 , timeout = 20000 ) else : self.crawl(response.url, save={'time' : time},callback=self.detail_page,validate_cert=False ,connect_timeout = 5000 , timeout = 20000 ) @config(priority=2 ) def detail_page (self, response ): title=response.doc('.wd_news_releases-detail > h1' ).text() time=response.save['time' ] content = '' for each in response.doc('.news_body > p' ).items(): content += each.text() url = response.url picture_url = '' picture_local_path = '' file_title = re.sub('[\/:*?"<>|]' ,'-' ,title) imgDir = self.dir_path for imgElem in response.doc('.detail_image > img' ).items(): imgUrl = imgElem.attr.src picture_url += imgUrl + ';' if imgUrl: extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 20000 ) for imgElem in response.doc('.PRN_ImbeddedAssetReference > p > img' ).items(): imgUrl = imgElem.attr.src picture_url += imgUrl + ';' if imgUrl: extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 30000 ) return { "title" :title, "introduction" :"null" , "time" :time, "content" :content, "keywords" :"null" , "name" :"boeing" , "source" :"原创" , "url" :url, "picture_url" :picture_url, "picture_local_path" :picture_local_path } def save_img (self,response ): content = response.content file_name = response.save["file_name" ] imgDir = response.save["imgDir" ] file_path = imgDir + file_name self.tool.save_img(content,imgDir,file_path) def on_result (self,result ): if not result or not result['title' ]: return sql = SQL() sql.insert('boeing' ,**result) class Tool : def save_img (self,content,imgDir,path ): if not os.path.exists(imgDir): os.makedirs(imgDir) f = open (path,"wb" ) f.write(content) f.close() def get_extension (self,url ): extension = url.split("." )[-1 ] return extension def get_name (self,url ): name=url.split("/" )[-1 ].split("." )[0 ] return name
单击save
回到pyspider dashboard页面
修改状态到running,单击run。查询数据库是否有数据写入。
Reference python学习资料 初学者不建议直接安装python!请安装Anaconda!
http://blog.csdn.net/qiushi_1990/article/details/78041375 http://idea.lanyus.com/ https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows https://www.zhihu.com/question/29238666 推荐:[计算机][Python实战:四周实现爬虫系统][中文][SWF] 。(我没看多少)
http://blog.csdn.net/u012162613/article/details/41929171 不贴网址了。网上搜中国大学MOOC嵩天老师的Python相关课程,从基础到各个方向都有。B站也可以看哦。
pyspider学习资料 https://binux.blog/ http://docs.pyspider.org/en/latest/tutorial/HTML-and-CSS-Selector/#index-page https://www.youtube.com/playlist?list=PLlOGeDt-ISLoiX7OyMHYT9t0DOUhL-pxi https://www.bilibili.com/video/av5354244?from=search&seid=3687842734548943914 http://demo.pyspider.org/ http://www.pyspider.cn/jiaocheng/pyspider-pyquery-14.html http://www.pyspider.cn/index.html http://blog.csdn.net/i_chaoren/article/details/62264414 http://blog.csdn.net/zaifendou/article/details/5746988 https://www.cnblogs.com/darkterror/p/6474211.html https://www.bilibili.com/video/av5862916?from=search&seid=6989261257840462106 http://blog.csdn.net/FeiSan/article/details/1887677 http://blog.csdn.net/u012827296/article/details/51236614
pyspider快捷启动命令 !pyspider快捷启动命令_为了提高cmd运行速度,直接在txt中修改,然后Ctrl+A粘贴到cmd中执行_cd到目录_md创建目录
1 2 3 4 5 F: md Crawl_data\demo cd Crawl_data\demo activate python2 pyspider all
可能会用到的安装包 只提供明细,不提供下载。
迷之·附录(代码) 代码集中车间233。
代码:结构_model_for_crawl_demo加注释版.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 from pyspider.libs.base_handler import *import refrom pyspider.database.mysql.mysqldb import SQLimport sys import osimport time as tifrom dateutil import parser reload(sys) sys.setdefaultencoding('utf8' ) DIR_PATH = "./" class Handler (BaseHandler ): headers= { "Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Accept-Encoding" :"gzip, deflate, sdch" , "Accept-Language" :"zh-CN,zh;q=0.8" , "Cache-Control" :"max-age=0" , "Connection" :"keep-alive" , "User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36" } crawl_config = { 'itag' : 'v1.1' , "headers" : headers, "timeout" : 100000 } def __init__ (self ): self.dir_path = DIR_PATH self.tool = Tool() @every(minutes=24 * 60 ) def on_start (self ): self.crawl('http://boeing.mediaroom.com/news-releases-statements' , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc('.archive_nav > a' ).items(): year=each.text() if (year != "Search" ): if (year=="2016" or year=="2015" ): self.crawl(each.attr.href, callback=self.news_page) def news_page (self, response ): for each in response.doc('.item' ).items(): time=each.find('div' ).eq(0 ).text() datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) self.crawl(each.find('div' ).find('a' ).attr.href, save={'time' : time},callback=self.news,connect_timeout = 5000 , timeout = 20000 ) for each_page in response.doc('.table_footer > b > a' ).items(): self.crawl(each_page.attr.href, callback=self.news_page2) def news_page2 (self, response ): for each in response.doc('.item' ).items(): time=each.find('div' ).eq(0 ).text() datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) self.crawl(each.find('div' ).find('a' ).attr.href, save={'time' : time},callback=self.news,connect_timeout = 5000 , timeout = 20000 ) def news (self, response ): time=response.save['time' ] if response.doc('#assets_20295_130083-117_tab_link' ): self.crawl(response.doc('#assets_20295_130083-117_tab_link' ).attr.href,save={'time' : time}, callback=self.detail_page,validate_cert=False ,connect_timeout = 5000 , timeout = 20000 ) else : self.crawl(response.url, save={'time' : time},callback=self.detail_page,validate_cert=False ,connect_timeout = 5000 , timeout = 20000 ) @config(priority=2 ) def detail_page (self, response ): title=response.doc('.wd_news_releases-detail > h1' ).text() time=response.save['time' ] content = '' for each in response.doc('.news_body > p' ).items(): content += each.text() url = response.url picture_url = '' picture_local_path = '' file_title = re.sub('[\/:*?"<>|]' ,'-' ,title) imgDir = self.dir_path for imgElem in response.doc('.detail_image > img' ).items(): imgUrl = imgElem.attr.src picture_url += imgUrl + ';' if imgUrl: extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 20000 ) for imgElem in response.doc('.PRN_ImbeddedAssetReference > p > img' ).items(): imgUrl = imgElem.attr.src picture_url += imgUrl + ';' if imgUrl: extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 30000 ) return { "title" :title, "introduction" :"null" , "time" :time, "content" :content, "keywords" :"null" , "name" :"boeing" , "source" :"原创" , "url" :url, "picture_url" :picture_url, "picture_local_path" :picture_local_path } def save_img (self,response ): content = response.content file_name = response.save["file_name" ] imgDir = response.save["imgDir" ] file_path = imgDir + file_name self.tool.save_img(content,imgDir,file_path) def on_result (self,result ): if not result or not result['title' ]: return sql = SQL() sql.insert('boeing' ,**result) class Tool : def save_img (self,content,imgDir,path ): if not os.path.exists(imgDir): os.makedirs(imgDir) f = open (path,"wb" ) f.write(content) f.close() def get_extension (self,url ): extension = url.split("." )[-1 ] return extension def get_name (self,url ): name=url.split("/" )[-1 ].split("." )[0 ] return name
代码:功能for_compositesworld(复合材料世界) 爬虫程序_详注 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 from pyspider.libs.base_handler import * import re from pyspider.database.mysql.mysqldb import SQLimport sys import os import time as ti from dateutil import parser reload(sys) sys.setdefaultencoding('utf8' ) DIR_PATH = "./" class Handler (BaseHandler ): headers= { "Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Accept-Encoding" :"gzip, deflate, sdch" , "Accept-Language" :"zh-CN,zh;q=0.8" , "Cache-Control" :"max-age=0" , "Connection" :"keep-alive" , "User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36" } crawl_config = { 'itag' : 'v1.1' , "headers" : headers, "timeout" : 100000 } def __init__ (self ): self.dir_path = DIR_PATH self.tool = Tool() @every(minutes=24 * 60 ) def on_start (self ): self.crawl('https://www.compositesworld.com/news/list' ,validate_cert=False , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc('.headline > a' ).items(): self.crawl(each.attr.href, validate_cert=False ,callback=self.detail_page) next = response.doc('a[aria-label="Next"]' ) self.crawl(next .attr.href,validate_cert=False , connect_timeout = 5000 , timeout = 20000 ,callback=self.index_page) @config(priority=2 ) def detail_page (self, response ): title = response.doc('.content-headline' ).text() introduction = response.doc('.col-sm-12 > h1' ).text() time = response.doc('.cell-vert-center > div > span' ).text() time = time[10 :] datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) content = response.doc('#short > div > div > p' ).text() url = response.url picture_url = '' picture_local_path = '' file_title = re.sub('[\/:*?"<>|]' ,'-' ,title) imgDir = self.dir_path for imgElem in response.doc('picture > img' ).items(): imgUrl = imgElem.attr.src imgUrl = imgUrl[:-10 ] picture_url += imgUrl + ';' if imgUrl: extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 20000 ) return { "title" :title, "introduction" :introduction, "time" :time, "content" :content, "keywords" :"null" , "name" :"compositesworld" , "source" :"原创" , "url" :url, "picture_url" :picture_url, "picture_local_path" :picture_local_path } def save_img (self,response ): content = response.content file_name = response.save["file_name" ] imgDir = response.save["imgDir" ] file_path = imgDir + file_name self.tool.save_img(content,imgDir,file_path) def on_result (self,result ): if not result or not result['title' ]: return sql = SQL() sql.insert('compositesworld' ,**result) class Tool : def save_img (self,content,imgDir,path ): if not os.path.exists(imgDir): os.makedirs(imgDir) f = open (path,"wb" ) f.write(content) f.close() def get_extension (self,url ): extension = url.split("." )[-1 ] return extension def get_name (self,url ): name=url.split("/" )[-1 ].split("." )[0 ] return name
代码:封装for_jeccomposites(JEC) 伪宏控制__范式编程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 project_name = "jeccomposites" website_url_initial = 'http://www.jeccomposites.com/knowledge/international-composites-news' detail_page_css = '.nodetitle > a' next_page_css = '.pager-next > a' title_css = '.content > h1' introduction_css = '.content-block-txt > p' time_css = '.content-block-txt > div' content_css = '.block-system > div > div div > div > p' img_css = '.content > a > img' keywords_css = 'null' source_declaration = "原创" from pyspider.libs.base_handler import * import re from pyspider.database.mysql.mysqldb import SQLfrom pyspider.database.mysql.mysqldb_new import SQL as SQL_newimport sys import os import time as ti from dateutil import parser sql_new = SQL_new() sql_new.create_table(project_name) path_for_project = "./" +project_name+"/" if not os.path.exists(path_for_project): os.makedirs(path_for_project) DIR_PATH = path_for_project else : DIR_PATH = path_for_project reload(sys) sys.setdefaultencoding('utf8' ) class Handler (BaseHandler ): headers= { "Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Accept-Encoding" :"gzip, deflate, sdch" , "Accept-Language" :"zh-CN,zh;q=0.8" , "Cache-Control" :"max-age=0" , "Connection" :"keep-alive" , "User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36" } crawl_config = { 'itag' : 'v1.1' , "headers" : headers, "timeout" : 100000 } def __init__ (self ): self.dir_path = DIR_PATH self.tool = Tool() @every(minutes=24 * 60 ) def on_start (self ): self.crawl(website_url_initial,validate_cert=False , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc(detail_page_css).items(): self.crawl(each.attr.href, validate_cert=False ,callback=self.detail_page) next = response.doc(next_page_css) self.crawl(next .attr.href,validate_cert=False , connect_timeout = 5000 , timeout = 20000 ,callback=self.index_page) @config(priority=2 ) def detail_page (self, response ): title = title_css if (title_css != 'null' ): title = response.doc(title_css).text() introduction = introduction_css if (introduction_css != 'null' ): introduction = response.doc(introduction_css).text() time = time_css if (time_css != 'null' ): time = response.doc(time_css).text() datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) content = content_css if (content_css != 'null' ): content = response.doc(content_css).text() keywords = keywords_css if (keywords_css != 'null' ): keywords = response.doc(keywords_css).text() url = response.url picture_url = '' picture_local_path = '' file_title = re.sub('[\/:*?"<>|]' ,'-' ,title) imgDir = self.dir_path for imgElem in response.doc(img_css).items(): imgUrl = imgElem.attr.src if imgUrl and self.tool.get_name(imgUrl) != 'logo' : picture_url += imgUrl + ';' extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 20000 ) return { "title" :title, "introduction" :introduction, "time" :time, "content" :content, "keywords" :keywords, "name" :project_name, "source" :source_declaration, "url" :url, "picture_url" :'null' if picture_url == '' else picture_url, "picture_local_path" :'null' if picture_local_path == '' else picture_local_path } def save_img (self,response ): content = response.content file_name = response.save["file_name" ] imgDir = response.save["imgDir" ] file_path = imgDir + file_name self.tool.save_img(content,imgDir,file_path) def on_result (self,result ): if not result or not result['title' ]: return sql = SQL() sql.insert(project_name,**result) class Tool : def save_img (self,content,imgDir,path ): if not os.path.exists(imgDir): os.makedirs(imgDir) f = open (path,"wb" ) f.write(content) f.close() def get_extension (self,url ): extension = url.split("." )[-1 ] return extension def get_name (self,url ): name=url.split("/" )[-1 ].split("." )[0 ] return name
代码:forcompositesworld(复合材料世界) 基于JEC通用化代码模板_改进版 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 project_name = "compositesworld" website_url_initial = 'https://www.compositesworld.com/news/list' detail_page_css = '.headline > a' next_page_css = 'a[aria-label="Next"]' title_css = '.content-headline' introduction_css = '.col-sm-12 > h1' time_css = '.clearfix span[property="dc:created"]' content_css = '#short > div > div > p' img_css = 'picture > img' keywords_css = 'null' source_declaration = "原创" from pyspider.libs.base_handler import * import re from pyspider.database.mysql.mysqldb import SQLfrom pyspider.database.mysql.mysqldb_new import SQL as SQL_newimport sys import os import time as ti from dateutil import parser sql_new = SQL_new() sql_new.create_table(project_name) path_for_project = "./" +project_name+"/" if not os.path.exists(path_for_project): os.makedirs(path_for_project) DIR_PATH = path_for_project else : DIR_PATH = path_for_project reload(sys) sys.setdefaultencoding('utf8' ) class Handler (BaseHandler ): headers= { "Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Accept-Encoding" :"gzip, deflate, sdch" , "Accept-Language" :"zh-CN,zh;q=0.8" , "Cache-Control" :"max-age=0" , "Connection" :"keep-alive" , "User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36" } crawl_config = { 'itag' : 'v1.1' , "headers" : headers, "timeout" : 100000 } def __init__ (self ): self.dir_path = DIR_PATH self.tool = Tool() @every(minutes=24 * 60 ) def on_start (self ): self.crawl(website_url_initial,validate_cert=False , callback=self.index_page) @config(age=10 * 24 * 60 * 60 ) def index_page (self, response ): for each in response.doc(detail_page_css).items(): self.crawl(each.attr.href, validate_cert=False ,callback=self.detail_page) next = response.doc(next_page_css) self.crawl(next .attr.href,validate_cert=False , connect_timeout = 5000 , timeout = 20000 ,callback=self.index_page) @config(priority=2 ) def detail_page (self, response ): title = title_css if (title_css != 'null' ): title = response.doc(title_css).text() introduction = introduction_css if (introduction_css != 'null' ): introduction = response.doc(introduction_css).text() time = time_css if (time_css != 'null' ): time = response.doc(time_css).text() time.strip() time = time[10 :] datetime_struct = parser.parse(time) time=datetime_struct.strftime('%Y-%m-%d' ) content = content_css if (content_css != 'null' ): content = response.doc(content_css).text() keywords = keywords_css if (keywords_css != 'null' ): keywords = response.doc(keywords_css).text() url = response.url picture_url = '' picture_local_path = '' file_title = re.sub('[\/:*?"<>|]' ,'-' ,title) imgDir = self.dir_path for imgElem in response.doc(img_css).items(): imgUrl = imgElem.attr.src imgUrl = imgUrl[:-10 ] if imgUrl: picture_url += imgUrl + ';' extension = self.tool.get_extension(imgUrl) name = self.tool.get_name(imgUrl) file_name = name + "." + extension picture_local_path += ';' + file_name self.crawl(imgUrl,callback=self.save_img,save={"file_name" :file_name, "imgDir" :imgDir},validate_cert=False , connect_timeout = 5000 , timeout = 20000 ) return { "title" :title, "introduction" :introduction, "time" :time, "content" :content, "keywords" :keywords, "name" :project_name, "source" :source_declaration, "url" :url, "picture_url" :'null' if picture_url == '' else picture_url, "picture_local_path" :'null' if picture_local_path == '' else picture_local_path } def save_img (self,response ): content = response.content file_name = response.save["file_name" ] imgDir = response.save["imgDir" ] file_path = imgDir + file_name self.tool.save_img(content,imgDir,file_path) def on_result (self,result ): if not result or not result['title' ]: return sql = SQL() sql.insert(project_name,**result) class Tool : def save_img (self,content,imgDir,path ): if not os.path.exists(imgDir): os.makedirs(imgDir) f = open (path,"wb" ) f.write(content) f.close() def get_extension (self,url ): extension = url.split("." )[-1 ] return extension def get_name (self,url ): name=url.split("/" )[-1 ].split("." )[0 ] return name
代码:testpro 通过调用MySQLnew实现自动创建列表_demo 1 2 3 4 from pyspider.database.mysql.mysqldb_new import SQLsql = SQL() sql.create_table("test_for_auto_table_maker" )
代码:mysqldb_new(库) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 from six import itervaluesimport MySQLdbfrom sqlalchemy import *from sqlalchemy.orm import *from sqlalchemy.databases import mysqlclass SQL (): def __init__ (self ): hosts = 'localhost' username = 'root' password = '233333' database = 'pyspider' charsets = 'utf8' port_number = 3307 self.connection = False try : self.conn = MySQLdb.connect(host = hosts,user = username,passwd = password,db = database,charset = charsets, port = port_number) self.cursor = self.conn.cursor() self.cursor.execute("set names " +charsets) self.connection = True except Exception,e: print "Cannot Connect To Mysql!/n" ,e def escape (self,string ): return '%s' % string def insert (self,tablename=None ,**values ): if self.connection: tablename = self.escape(tablename) if values: _keys = "," .join(self.escape(k) for k in values) _values = "," .join(['%s' ,]*len (values)) sql_query = "insert into %s (%s) values (%s)" % (tablename,_keys,_values) else : sql_query = "replace into %s default values" % tablename try : if values: self.cursor.execute(sql_query,list (itervalues(values))) else : self.cursor.execute(sql_query) self.conn.commit() return True except Exception,e: print "An Error Occured: " ,e return False def create_table (self,project_name ): engine = create_engine('mysql+mysqlconnector://root:fdzxks@localhost:3307/pyspider' ) metadata = MetaData(engine) user = Table(project_name, metadata, Column('title' , VARCHAR(255 )), Column('introduction' , mysql.MSLongText), Column('time' , VARCHAR(255 )), Column('content' , mysql.MSLongText), Column('keywords' , VARCHAR(255 )), Column('name' , VARCHAR(255 )), Column('source' , VARCHAR(255 )), Column('url' , VARCHAR(255 )), Column('picture_url' , mysql.MSLongText), Column('picture_local_path' , mysql.MSLongText), ) metadata.create_all(engine) conn = engine.connect()