FastText体验笔记。
References
fastText,FastText 中文文档 - ApacheCN,FastText使用指南| 竹园山庄
Paper:
Enriching Word Vectors with Subword Information
这篇论文提出了用 word n-gram 的向量之和来代替简单的词向量的方法,以解决简单 word2vec 无法处理同一词的不同形态的问题。fastText 中提供了 maxn 这个参数来确定 word n-gram 的 n 的大小。
Bag of Tricks for Efficient Text Classification
这篇论文提出了 fastText 算法,该算法实际上是将目前用来算 word2vec 的网络架构做了个小修改,原先使用一个词的上下文的所有词向量之和来预测词本身(CBOW 模型),现在改为用一段短文本的词向量之和来对文本进行分类。
FastText.zip: Compressing text classification models
这篇论文讲fastText的模型压缩(存储空间)。这样,fastText甚至可以移植到手机端。
fastText,智慧与美貌并重的文本分类及向量化工具| 机器之心
fastText能够做到效果好,速度快,主要依靠两个秘密武器:一是利用了词内的n-gram信息(subword n-gram information),二是用到了层次化Softmax回归(Hierarchical Softmax)的训练trick。
Text Classification Simplified with Facebook’s FastText
NLP︱高级词向量表达(二)——FastText(简述、学习笔记) - 素质云笔记 …
fastText 源码分析- Helei’s Tech Notes
Introduction
FastText可以进行:
- 表示学习(学习词语的embedding向量)
- word2vec优化版,用了Subword的信息,速度是不会提升的,只是效果方面的改进,对于中文貌似完全没用
- 文本分类(尤其是句子分类)
- 把句子每个word的vec求平均,然后直接用简单的LR分类就行(单层神经网络)
特性表
| 特性 | Liblinear | 深度学习 | fastText |
|---|---|---|---|
| 梯度下降方法 | newGLMNET | BGD*depth | SGD+线衰lr |
| NGram | 训练 | 训练+Hash存储 | |
| Softmax | S | S | HS |
| 深度 | 单层 | 多层 | 单层 |
| 架构 | 全连接 | 平均 | |
| 词向量 | 可选 | 可选 | |
| Thread | 单线程 | 多线程 | 多线程 |
传统学习指: LIBLINEAR: A library for large linear classification
环境
第一步当然是安装环境辣。
FastText源码采用
C++实现。
Linux
进入Linux服务器实验目录:
1 | $ git clone https://github.com/facebookresearch/fastText.git |
make寻找目录下的Makefile文件,并根据其内容进行项目编译。
Python
fasttext也能在python上便捷地使用:https://github.com/facebookresearch/fastText/tree/master/python
1 | $ git clone https://github.com/facebookresearch/fastText.git |
Microsoft Visual C++ Build Tools下载/解决Visual C++ 14.0 is required …
原理
文本分类需要CNN? No!fastText完美解决你的需求(前篇)
文本分类需要CNN?No!fastText完美解决你的需求(后篇)
如何评价Word2Vec作者提出的fastText算法?深度学习是否在文本分类等简单任务上没有优势?
How does FastText classifier work under the hood?
Is FastText faster than Word2vec? Why?
fastText(二):微博短文本下fastText的应用(一)
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
fastText结合了自然语言处理和机器学习中最成功的理念。这些包括了使用词袋以及n-gram袋表征语句,还有使用子字(subword)信息,并通过隐藏表征在类别间共享信息。我们另外采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程!
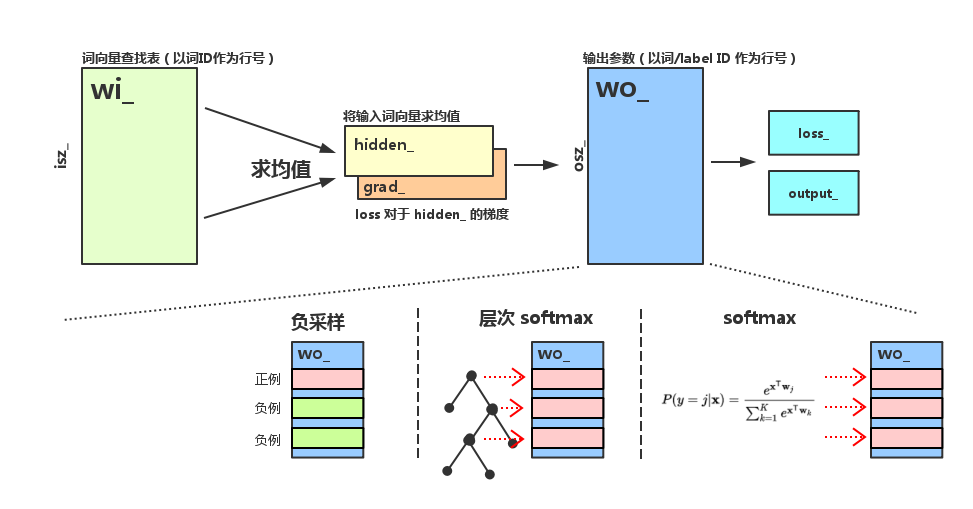
fastText方法包含三部分,模型架构,层次SoftMax和N-gram特征。
模型架构
fasttext是一个单层网络。
fasttext将Ngrams也当做词训练word2vec模型;用CBOW的思路来做分类。(fasttext有一个有监督的模式,但是模型等同于
cbow,只是target变成了label而不是word)

fasttext只有1层神经网络,属于所谓的shallow learning,但是fasttext的效果并不差,而且具备学习和预测速度快的优势,在工业界这点非常重要。它比一般的神经网络模型的精确度还要高。
Model
DAN (deep averaging network)
Deep Unordered Composition Rivals Syntactic Methods for Text Classification
论文笔记:Deep Unordered Composition Rivals Syntactic Methods for Text Classification
fastText简而言之,就是把文档中所有词通过lookup table变成向量,取平均后直接用线性分类器得到分类结果。fastText和ACL-15上的deep averaging network (DAN,如下图)非常相似,区别就是去掉了中间的隐层。两篇文章的结论也比较类似,也是指出对一些简单的分类任务,没有必要使用太复杂的网络结构就可以取得差不多的结果。
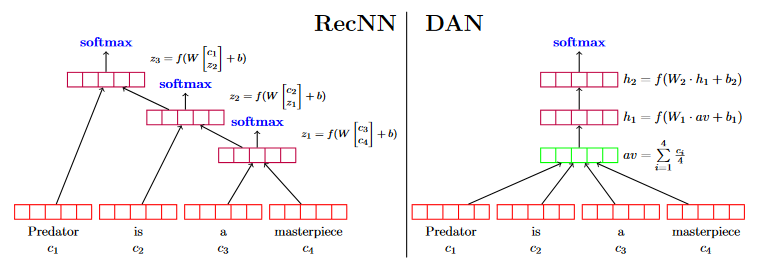
RecNN: Recursive Neural Nets(递归神经网络)。
对于任意数量的词语(n),DAN计算2层非线性层,而RecNN需要计算n-1层。
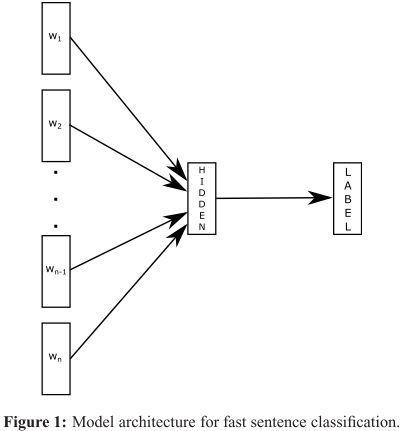
fastText
下面是fastText的架构:
Word2vec
Efficient Estimation of Word Representations in Vector Space
Distributed Representations of Words and Phrases and their Compositionality
fastText 提供了两种用于计算词表示的模型:skipgram 和 cbow (‘continuous-bag-of-words’)。
上下文:指在目标词左边和右边的固定单词数和。
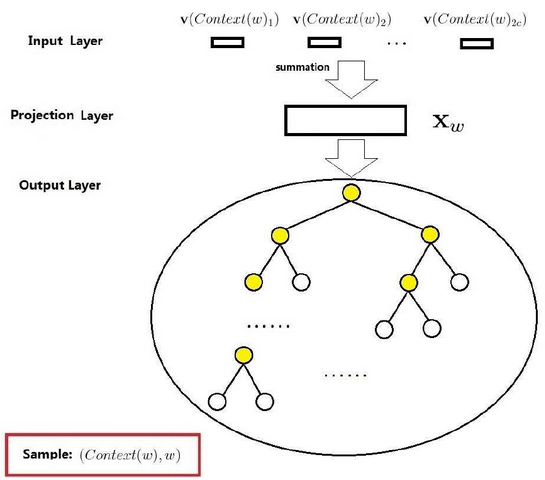
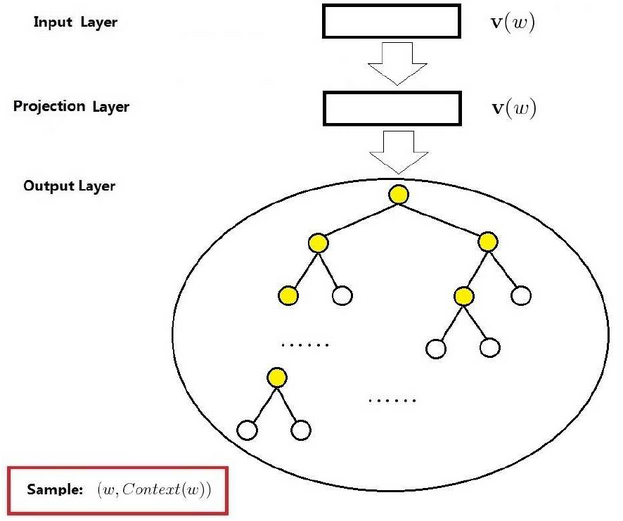
cbow 模型是根据目标词的上下文来预测目标词。skipgram 模型是学习近邻的单词来预测目标单词。

skipgram模型会比cbow模型在 subword information(子词信息)方面效果更好。
神经语言模型
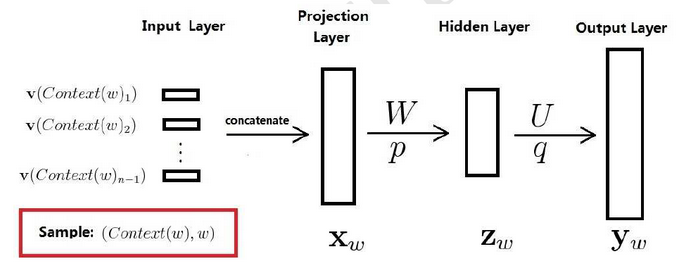
神经语言模型又常常被简记为下图:
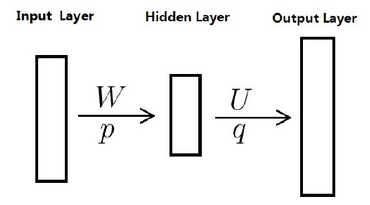
CBOW
Skip-gram
层次softmax

N-gram
来源于马尔可夫链。
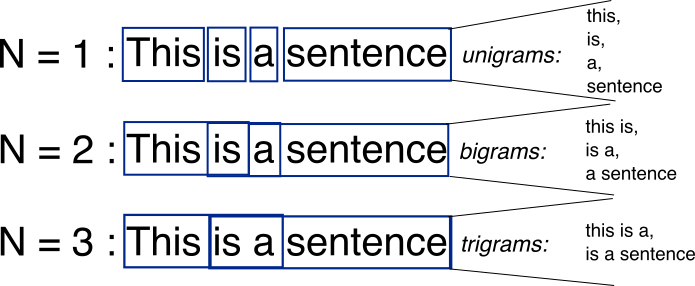
N-gram features:
- 只用unigram的话会丢掉word order信息,所以通过加入N-gram features进行补充
- 用hashing来减少N-gram的存储
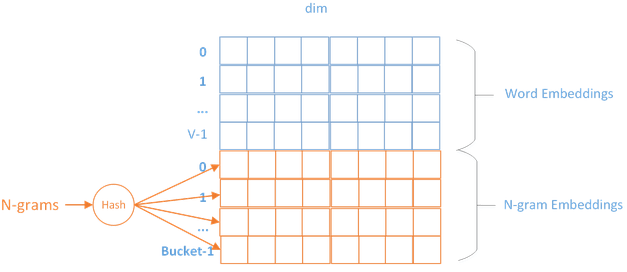
由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。Fasttext采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。如下图所示:
源码
fastText在实现上很考究。源码采用C++实现。
Text Classification 文本分类
确认进入实验目录:***/***/fastTest.
运行以下命令:(不加参数)
1 | ./fasttext |
则可以显示功能列表。
1 | >> ./fasttext |
| 选项 | 用途 |
|---|---|
| supervised | 分类任务,训练模型 |
| quantize | 压缩模型 |
| test | 分类任务,测试模型 |
| predict | 分类任务,预测 |
| predict-prob | 分类任务,预测,并带着预测概率输出 |
| skipgram | 词embedding任务,skipgram模型 |
| cbow | 词embedding任务,cbow 模型 |
| print-word-vectors | 打印词embedding向量,需要输入一个模型 |
| print-sentence-vectors | 打印句子embedding向量,需要输入一个模型 |
| print-ngrams | 打印ngram,需要输入一个模型和一个词 |
| nn | 搜索最近邻向量 |
| analogies | 对向量做一些加减运算,比如“北京 - 中国 + 日本”,会搜出“东京” |
| dump | 导出训练的参数和模型 |
文本分类教程中, we mainly use the supervised, test and predictsubcommands, which corresponds to learning (and using) text classifier.
For an introduction to the other functionalities of fastText, please see the tutorial about learning word vectors.
Cooking 实验
获得数据
1 | >> wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz |
All the labels start by the
__label__prefix, which is how fastText recognize what is a label or what is a word.(其实后面也可以在训练里通过-label参数改改)
wget [url]获取云端文件,&&是短路写法,tar xvzf解压缩。head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
数据切分
观测数据:
1 | >> wc cooking.stackexchange.txt |
输出说明:行数 单词数 字节数 文件名
切分:(Our full dataset contains 15404 examples.)
1 | >> head -n 12404 cooking.stackexchange.txt > cooking.train |
-n输入行数,>输出重定向。
训练
1 | >> ./fasttext supervised -input cooking.train -output model_cooking |
The
-inputcommand line option indicates the file containing the training examples, while the-outputoption indicates where to save the model. At the end of training, a filemodel_cooking.bin, containing the trained classifier, is created in the current directory.
训练参数表:(Or here)
| 参数 | 作用 | 默认值 |
|---|---|---|
| -input | 训练数据 | |
| -output | 模型输出,会输出模型和embedding结果,后缀是.vec和.bin | |
| -lr | 学习率 | 0.1 |
| -epoch | 迭代次数 | 5 |
| -neg | 负采样个数 | 5 |
| -label | 类别前缀 | __label__ |
| -loss | 损失函数 {ns, hs, softmax},负采样, 霍夫曼层次softmax,softmax | softmax |
| -ws | 学习embedding模型时,考虑上下文词的个数,窗口宽度 | 5 |
| -pretrainedVectors | 引入预训练的词向量 | |
| -dim | embedding的向量维度 | 100 |
| -bucket | 哈希桶(样本量很大时提速) | |
| -thread | 线程数 | 12 |
| -saveOutput | 是否输出参数需要保存 | false |
| -verbose | 冗长等级 | 2 |
| -minCount | 最小词频过滤 | 0 |
| -minCountLabel | 最小类别样本数过滤 | |
| -wordNgrams | 最大ngram | 1 |
| -minn | 字符ngram最小长度 | 0 |
| -maxn | 字符ngram最大长度 | 0 |
| -t | 采样阈值 | 0.0001 |
| -lrUpdateRate | 多少次更新后改变学习率 | 100 |
| -cutoff | 最大保留的词和ngram串数量 | 0 |
| -retrain | 如果 cutoff 设置了,是否需要优化embedding输出 | false |
| -qnorm | whether the norm is quantized separately | false |
| -qout | 分类器是否需要quantized | false |
| -dsub | 每个子向量的数量 | 2 |
测试
直接测试
It is possible to directly test our classifier interactively, by running the command:
1 | >> ./fasttext predict model_cooking.bin - |
and then typing a sentence. Let’s first try the sentence:
Which baking dish is best to bake a banana bread ?
The predicted tag is baking which fits well to this question. Let us now try a second example:
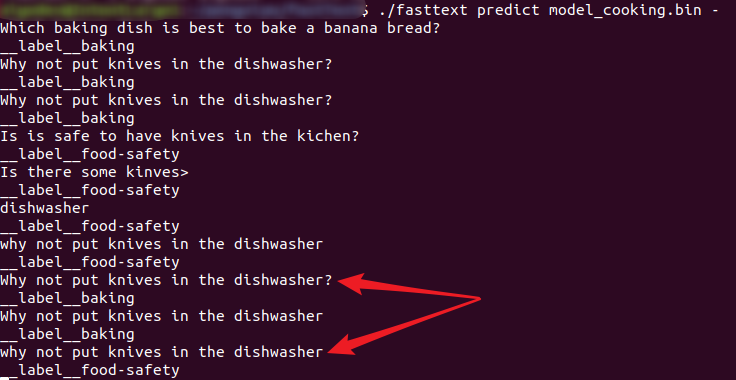
Why not put knives in the dishwasher?
The label predicted by the model is food-safety, which is not relevant. (实测这里也是baking,而且,该模型似乎对大小写敏感,见下图)Somehow, the model seems to fail on simple examples.
To get a better sense of its quality, let’s test it on the validation data by running:
1 | >> ./fasttext test model_cooking.bin cooking.valid |
The output of fastText are the precision at one (P@1) and the recall at one (R@1). We can also compute the precision at five and recall at five with:
1 | >> ./fasttext test model_cooking.bin cooking.valid 5 0.1 |
machine learning - What does Prec@1 in fastText mean? - Data …
Evaluation measures (information retrieval) - Wikipedia#Precision_at_K)
文本分类实验
实验记录表
| 实验 | 分词方式 | 测试结果 |
|---|---|---|
| 1 | 无分词 | N 61363 P@1 0.264 R@1 0.264 |
| 2 | 分字[default] | N 61363 P@1 0.772 R@1 0.772 |
| 3 | Jieba[common] | N 61363 P@1 0.768 R@1 0.768 |
| 4 | 分字[default] + -epoch 25 |
N 61363 P@1 0.827 R@1 0.827 |
| 5 | 分字[default] + -lr 0.3 |
N 61363 P@1 0.748 R@1 0.748 |
| 6 | 分字[default] + -epoch 30 -wordNgrams 2运行速度骤降 |
N 61363 P@1 0.821 R@1 0.821 |
| 7 | 分字[default] + -epoch 30 -wordNgrams 2 -loss hs运行速度明显提升,性能下降 层次sortmax |
N 61363 P@1 0.761 R@1 0.761 |
| 8 | 分字[default] + 标点过滤 +-epoch 25 |
N 61363 P@1 0.801 R@1 0.801 |
| 9 | 分字[default] + 预训练词向量[300维]-dim 300 |
N 61363 P@1 0.862 R@1 0.862 |
| 10 | 分字[default] + 预训练词向量[300维]+-epoch 30 -wordNgrams 2 |
N 61363 P@1 0.909 R@1 0.909 |
实验的测试结果波动在5%左右。
分层 softmax 是完全 softmax 损失函数的一种近似, 它能够在大量类的数据上高效训练. 这通常会损失一些精确度.
实验流程
将修改后的文件传到服务器上。
先修改意图label的形式,与fastText的API进行配对。
分字
1 | import pandas as pd |
分词
类似的。用jieba。
输出概率
predict-prob + >输出重定向到文件。
优化
- 预处理数据 ;
- 改变迭代次数 (使用选项
-epoch, 标准范围[5 - 50]) ; - 改变学习速率 (使用选项
-lr, 标准范围[0.1 - 1.0]) ; - 使用 word n-grams (使用选项
-wordNgrams, 标准范围[1 - 5]). - 引入预训练的字向量
预处理数据
1 | punc = punctuation + r" u‘.,;《》?!“”‘’@#¥%…&×()——+【】{};;●,。&~、|\s::‘" |
实测没有明显效果。
过拟合问题
fasttext存在过拟合问题,在训练集上的精度(98)远高于测试集(90%)。
但fasttext并没有引入正则化。