“Intro to Computer Systems” is a CS course held by CMU with course number CS213. Its home page says:
The ICS course provides a programmer’s view of how computer systems execute programs, store information, and communicate. It enables students to become more effective programmers, especially in dealing with issues of performance, portability and robustness. It also serves as a foundation for courses on compilers, networks, operating systems, and computer architecture, where a deeper understanding of systems-level issues is required. Topics covered include: machine-level code and its generation by optimizing compilers, performance evaluation and optimization, computer arithmetic, memory organization and management, networking technology and protocols, and supporting concurrent computation.
I note down some of the good stuff in case I forgot sometime. But mostly just a review before final test, don’t expect too much LOL.
Video resource on bilibili is: Here (2015 Fall) or Here(2017 Fall). In case you need it.
Website of this course: https://www.cs.cmu.edu/~213/
Textbook PDF: Computer Systems: A Programmer’s Perspective(2rd edition),Chinese version; 3rd edition on amazon.
Lecture notes: https://www.cs.cmu.edu/~213/schedule.html
Test PDF: https://www.cs.cmu.edu/~213/exams.html, test(answer), Moc, NE
Review Slides(Chinese): review
Overview
Ex.1: Is $x^2 \geq 0$ ?
- Float’s: Yes!
- Int’s: Not quiet…
- 40000$\times$40000=1600000000
- 50000$\times$50000=-179496729 (overflow)
Ex.2: Is (x+y)+z = x+(y+z) ?
- Float’s:
- (1e20+ -1e20) +2.14 = 3.14
- 1e20+ (-1e20 +2.14) = 0 (lose precision)
Sometimes this kind of issue(corner cases) can be essential! (Even though most of time it doesn’t matter)
Get to know assembly(汇编).
Get to know memory matters.
Ex.3: (Memory referencing bugs)

Double type has 2 bytes.( refer to a[2] & a[3])
System can be vulnerable by this.
Ex.4. (Memory system performance)

Those two codes’ performance differs from each other as almost 10 times on speed.
Showing as follows: (See in the Memory-Cache chapter, called “Memory Mountain”)
![]()
A programmer ‘s perspective.
- thing need to know for whom really do the coding
David talks about how influential this course is. (Even a story about a bookstore in Peking University)
MORE(Course Resources)
There are more topics taught in this class about network programing including several chapter.
Seems the course reschedule at Jan 15th. I can’t access the slides now. The note ends here. (Still can, use the schedule below instead)
Schedule
15-213/18-213/15-513: Intro to Computer Systems, Fall 2018
Notes on links
- pptx links are to Powerpoint versions of the lectures
- pdf links are to Adobe Acrobat versions of the lectures
- code links are to directories containing code used for class demonstrations
- tar links are to archive files in TAR format. Use the tar command on a linux machine to unpack these
| Lecture/Recitation |
|---|
| Recitation 1: No recitation—Semester starts with first lecture |
| Overview (pptx , pdf , code) |
| Bits, Bytes, & Integers I (pptx , pdf , code) |
| Recitation 2: No recitation—Labor Day / Linux Boot Camp (pdf) |
| Bits, Bytes, & Integers II (pptx , pdf , code) |
| Floating Point (pptx , pdf) |
| Recitation 3: Datalab and Data Representations (pdf , handout , solution) |
| Machine Prog: Basics (pptx , pdf) |
| Machine Prog: Control (pptx , pdf) |
| Recitation 4: Bomb Lab (pdf , pptx , handout) |
| Machine Prog: Procedures (catchup-pptx , catchup-pdf , pptx , pdf) |
| Machine Prog: Data (pptx , pdf) |
| Recitation 5: Attack Lab and Stacks (pdf , pptx , activity) |
| Machine Prog: Advanced (pptx , pdf , code) |
Code Optimization (pptx , pdf , C Bootcamp slides pdf , pptx , activity) |
| Recitation 6: C Review (pdf , activity) |
| The Memory Hierarchy (pptx , pdf) |
| Cache Memories (pptx , pdf) |
| Recitation 7: Cache Lab and blocking (pptx , pdf) |
| Linking (pptx , pdf , code) |
| ECF: Exceptions & Processes (pptx , pdf , code) |
| 7pm - 9pm Exam Review in Rashid Auditorium |
| Recitation 8: Exam Review (pptx , pdf) |
| ECF: Signals & Nonlocal Jumps (pptx , pdf , code) |
| System Level I/O (pptx , pdf , code) |
| Recitation 9: Shell lab, processes, signals, and I/O (pdf , pptx) |
| Virtual Memory: Concepts (pptx , pdf) |
| Virtual Memory: Systems (pptx , pdf) |
| Recitation 10: TSHLab and Virtual memory (pptx , pdf) |
| Dynamic Memory Allocation: Basic (pptx , pdf) |
| Dynamic Memory Allocation: Advanced (pptx , pdf) |
| Recitation 11: Malloc lab (Part I) (pptx , pdf , code) |
| Network Programming (Part I) (pptx , pdf , code) |
| Network Programming (Part II) (pptx , pdf , code) |
| 7pm - 8pm Malloc Bootcamp in Rashid Auditorium (pdf) |
| Recitation 12: Malloc lab (Part II) (pptx , pdf , code) |
| Concurrent programming (pptx , pdf , code) |
| Synchronization: Basic (pptx , pdf , code) |
| Recitation 13: Proxy lab (pptx , pdf) |
| Synchronization: Advanced (pptx , pdf , code) |
| No lecture—Thanksgiving |
| Recitation 14: Synchronization (pptx , pdf) |
| Thread-Level Parallelism (pptx , pdf) |
| Future of Computing I (pptx , pdf) |
| Recitation 15: Exam review |
| Future of Computing II (pptx , pdf) |
| Final exam |
Exam
https://www.cs.cmu.edu/~213/exams.html
Representing&Processing of Information
Bits
- Binary: 11110001
- Decimal: 241
- Hexadecimal: 0xF1
Boolean Algebra
And(&&), Or(||), Not(~/!), Exclusive-Or / Xor(^)
Opearte on bit vectors: &, |
- can be used to represent sets
- 01101001 {0, 3, 5, 6}
- 76543210 ———1 means the set contains the element, 0 otherwise
| Operation | Name | Byte | Set |
|---|---|---|---|
& |
Intersection | 01000001 | {0, 6} |
| |
Union | 01111101 | {0, 2, 3, 4, 5, 6} |
^ |
Symmetric difference | 00111100 | {2, 3, 4, 5} |
~/! |
Complement | 10101010 | {1, 3, 5, 7} |
p && *p: avoids null pointer access
Shift Operators
- Left shift:
<< - Right shift:
>>
There is a difference between logical shift and arithmetical shift, see in the following pic: The negative num’s arithmetical right shift will fill in 1s. (Others are 0s)

Intergers
Unsigned & Signed
- Unsigned Values
- $U_{Min} = 0$
- 000…0
- $U_{Max} = 2^w - 1 $
- 111…1
- $U_{Min} = 0$
- Two’s Complement Values【求负:取反加一】
- $T_{Min} = -2^{w-1}$
- 100…0
- $T_{Max} = 2^{w-1} -1$
- 011…1
- $T_{Min} = -2^{w-1}$
- Other Values
- Minus 1
- 111…1
- Minus 1
Here is a graph: (4 bits)
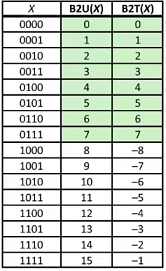
Notice:
Conversion Visualization
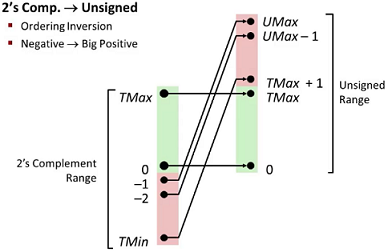
Casting(转换)
Principle: If there is a mix of unsigned and signed in single expression, signed values implicitly cast to unsigned.

Examples above are for W=32: TMIN=-2,147,483,648 ; TMAX=2,147,483,647.
1 | for(i = n-1; i >= 0; i--) |
1 | for(i = n-1; i - sizeof(str)>= 0; i--) |
Extension
Sign Extension
Principle: Add all 1s for the new blank.
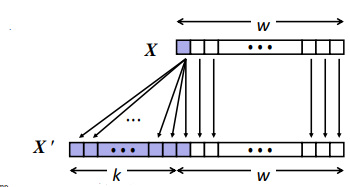
Unsigned
Principle: Add all 0s for the new blank. (Similarly)
Truncation(截断)
Unsigned: mod operation, Just drop it.
Signed: similar to mod (sign can be converted in the process)
Arithmetic
Addition
Unsigned Addition
Drop the overflowed part. (But when computing use extra bits)
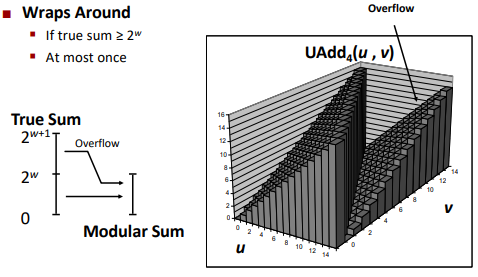
Two’s Complement Addition
Drop the overflowed part as well. (Will get the exact correct answer)
TAdd and UAdd have identical bit-level behavior.

Visualizing 2’s complement addition:
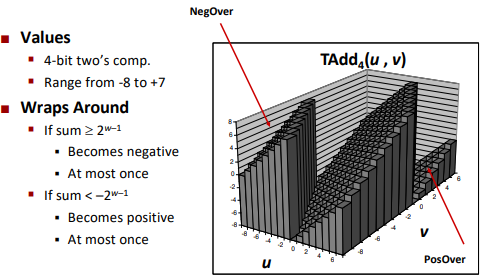
Multiplication
Unsigned multiplication
Still drop the overflowed part.
Signed multiplication
Drop the overflowed part. (sign can be converted in the process)
For negative numbers: drop the overflowed part will somehow still get right answer.
1101 -3 13(U) 1110 -4 14(U) 10110 6 6(U) Cause the actual effective bits are not really overflowed. (1101=101, 1110=10)
Shift
Power-of-2 Multiply with Shift
u<<k gives u*2^k(both signed and unsigned)
Shift is much faster than multiplication.
Unsigned Power-of-2 Divide with Shift
Use logical shift.(0s)
Signed Power-of-2 Divide with Shift
Use arithmetical shift.
| (>>)1010 | -6 |
|---|---|
| (>>)1101—->1110 | -3—->-2 |
| 1110—->1111 | -2—->-1 |
Trick: before you shift, you should add a bias.(For this example—->1)
But for c, it seems we don’t use bias. (右移向下舍入)
Summary
Why should I Use Unsigned?
In java there is no unsigned.
A new principle: Don’t use without understanding implications.

Counting down with Unsigned:

Finally, Why should I Use Unsigned?
- Do Use When Performing Modular Arithmetic
- Multiprecision arithmetic
- Do Use When Using Bits to Represent Sets
- Logical right shift, no sign extension
- Do Use In System Programming
- Bit masks, device commands,…
Representation in memory, pointers, strings
Byte-Oriented Memory Organization
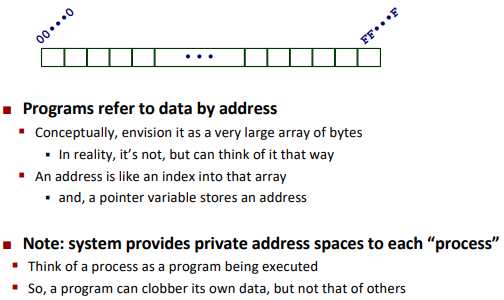
BUG: SegmentFault.
Trick: $2^{10}=1024\approx 1000=10^{3}$.
Machine Words: Any given computer has a “Word Size”.(32bit, 64bit)
For 32bits: limits addresses to 4GB(2^32 bytes)
For 64bits: limits addresses to 18PB(2^64 bytes)
Word-Oriented Memory Organization
Addresses Specify Byte Locations.
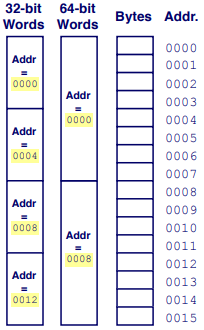
Example Data Representations:
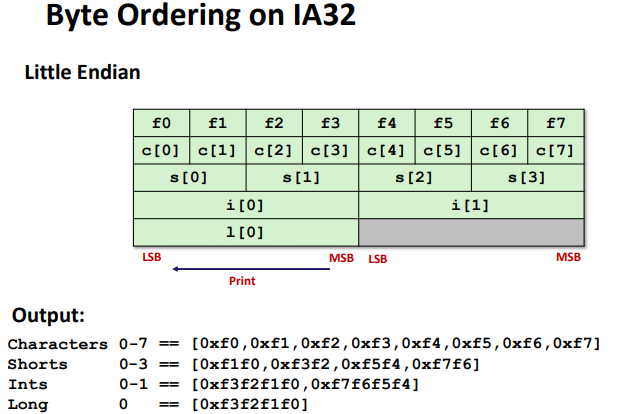
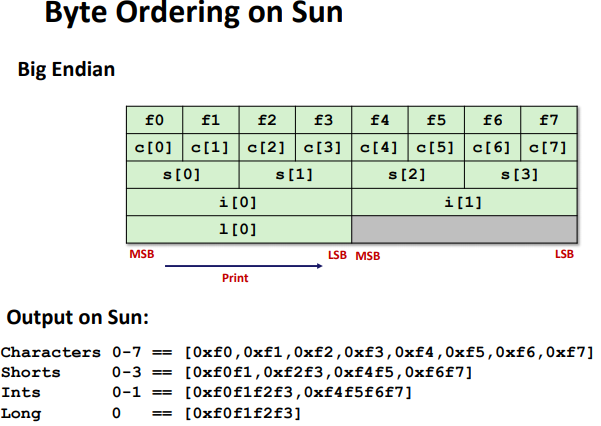
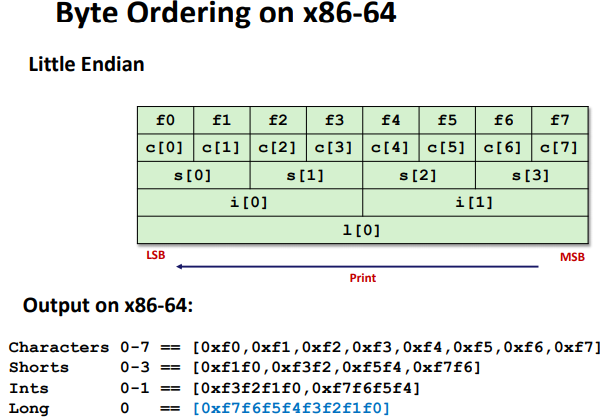
Byte Ordering(Endianness)
- Big Endian: Sun (Oracle SPARC), PPC Mac, Internet
- Least significant byte has highest address
- Little Endian: x86, ARM processors running Android, iOS, and Linux
- Least significant byte has lowest address
Ex:(Variable x has 4-byte value of 0x01234567, Address given by &x is 0x100)

Other representation can be see in the slides.
Puzzles: (32 bits for int)
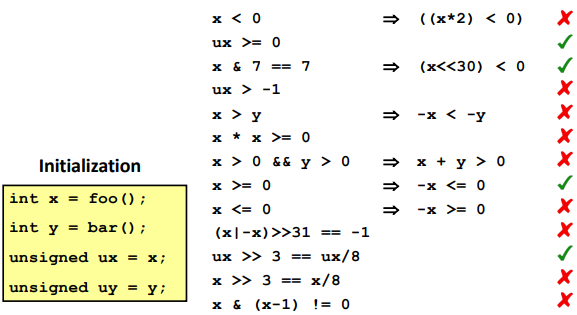
For
x > y ---> -x < y, note that there is a special occasion:For
(x|-x)>>31==-1, considerx=0.For
x>>3==x/8, using the ceil function(round down)
- for
/, always map close to 0- for
>>, always map with ceil function
Floating Point
Background
What is 1011.101(2) ?
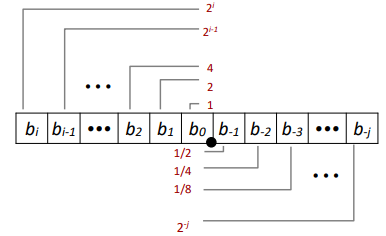
Representation:
- Bits to right of “binary point” represent fractional powers of 2
- Represents rational number
Here are some examples:
| Value | Representation |
|---|---|
| 5 3/4 | 101.11 |
| 2 7/8 | 10.111 |
| 1 7/16 | 1.0111 |
Limitation:
- Can only exactly represent numbers of the form x/2^k
- Other rational numbers have repeating bit representations
- Just one setting of binary point within the w
- Limited range of numbers (very small values? very large ( ——> floating point)
IEEE standard
Numerical Form:
- Sign bit s determines whether number is negative or positive
- Significand M normally a fractional value in range [1.0, 2.0).
- Exponent E weights value by power of two

There are mainly two types of floats:

Three “kinds” of floating point numbers:
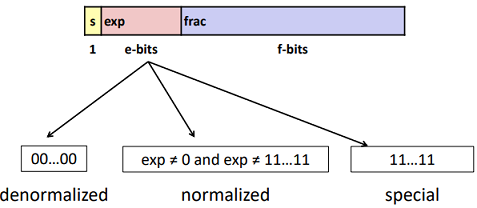
“Normalized” Values: (Very large and small numbers)
- When: exp ≠ 000…0 and exp ≠ 111…1
- Exponent coded as a biased value: E = exp – Bias (To represent small float numbers, just like 2’s complement)
- exp: unsigned value of exp field (Also: exp = E + Bias)
- Bias = $2^{k-1} - 1$, where k is number of exponent bits
- Single precision: 127 (exp: 1…254, E: -126…127
- ▪ Double precision: 1023 (exp: 1…2046, E: -1022…1023)
- Significand coded with implied leading 1: M = 1.xxx…x
- xxx…x: bits of frac field
- Minimum when frac=000…0 (M = 1.0)
- Maximum when frac=111…1 (M = 2.0 – ε)
- Get extra leading bit for “free”
- xxx…x: bits of frac field
Ex:
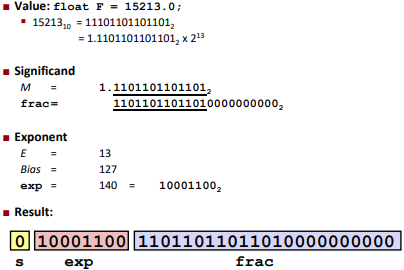
Note: 0<=Exp<=255, -127<=E<=128
Denormalized Values: ( represent values in $[0,1)$, especially 0)
- Condition: exp = 000…0
- Exponent value: E = 1 – Bias=$2-2^{k-1}$ =-126 (instead of exp – Bias) (why?)
- Significand coded with implied leading 0: M = 0.xxx…x
- xxx…x: bits of frac
- Case
- exp = 000…0, frac = 000…0
- Represents zero value
- Note distinct values: +0 and –0 (why? - signed)
- exp = 000…0, frac ≠ 000…0
- Numbers closest to 0.0
- Equispaced (mean distribution)
- exp = 000…0, frac = 000…0
Special Values: (Too Large to represent)
- Condition: exp = 111…1
- Case: exp = 111…1, frac = 000…0
- Represents value $\infty$ (infinity)
- Operation that overflows
- Both positive and negative
- E.g., $1.0/0.0 = +\infty ,−1.0/−0.0 = + \infty, 1.0/−0.0 = − \infty$ (Not number)
- Case: exp = 111…1, frac ≠ 000…0
- Not-a-Number (NaN)
- Represents case when no numeric value can be determined
- E.g., sqrt(–1),
Ex: (Do this and you will get the idea)

Example and properties
Tiny Floating Point Example:
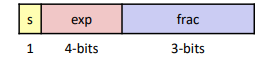
8-bit Floating Point Representation
▪ the sign bit is in the most significant bit
▪ the next four bits are the exp, with a bias of 7
▪ the last three bits are the frac
As you can see as follows, look at the red arrows. The mechanism actually give a smooth change from De. to Nor.
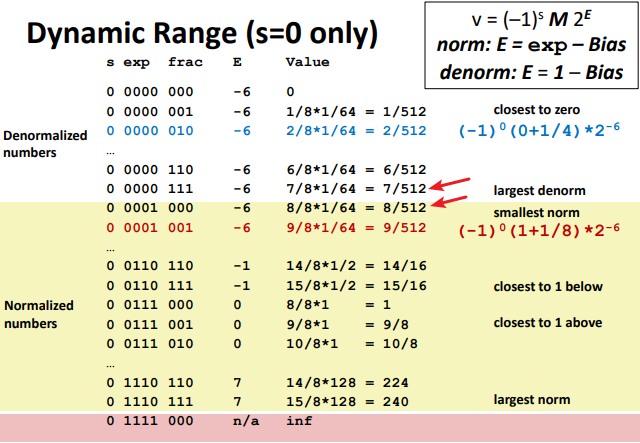
the distribution gets denser toward zero: (1s-3e-2f)
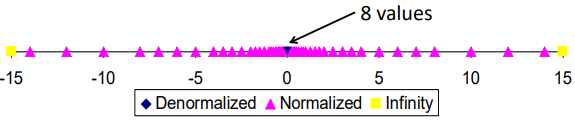
6-bit IEEE-like format (close-up view): (1s-3e-2f)

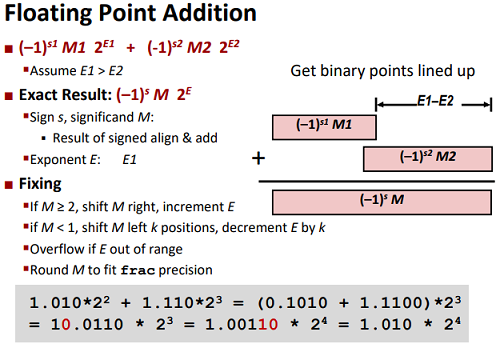
Operations
Floating Point Operations: Basic Idea
▪ First compute exact result
▪ Make it fit into desired precision
▪ Possibly overflow if exponent too large
▪ Possibly round to fit into frac
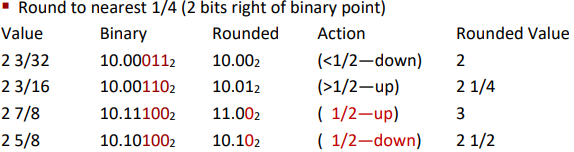
Rounding(取整)
Rounding Modes: (illustrate with $ rounding)
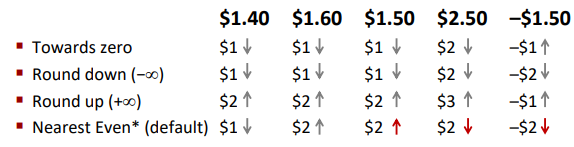
Round to nearest, but if half-way in-between then round to nearest even(偶)
Ex.
Addition
Multiplication

Lecture note: here.
Floating point in C
- C Guarantees Two Levels
- float single precision
- double double precision
- Conversions/Casting
- Casting between int, float, and double changes bit representation
- double/float → int
- Truncates fractional part
- Like rounding toward zero
- Not defined when out of range or NaN: Generally sets to TMin
- int → double
- Exact conversion, as long as int has ≤ 53 bit word size
- int → float
- Will round according to rounding mode
Floating Point Puzzles:

Summary

Machine Programming
Basics
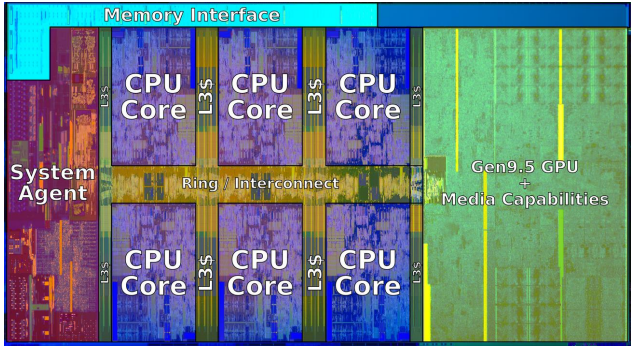
Intel x86 Processors : Complex instruction set computer (CISC).
The class will mainly use gcc complier.
2018 State of the Art: (Coffee Lake)
History blablabla…
C, assembly, machine code
Definitions
- Architecture: (also ISA: instruction set architecture) The parts of a processor design that one needs to understand for writing correct machine/assembly code
- Examples: instruction set specification, registers
- Machine Code: The byte-level programs that a processor executes
- Assembly Code: A text representation of machine code
- Microarchitecture: Implementation of the architecture
- Examples: cache sizes and core frequency
- Example ISAs:
▪ Intel: x86, IA32, Itanium, x86-64
▪ ARM: Used in almost all mobile phones
▪ RISC V: New open-source ISA
Assembly/Machine Code View:
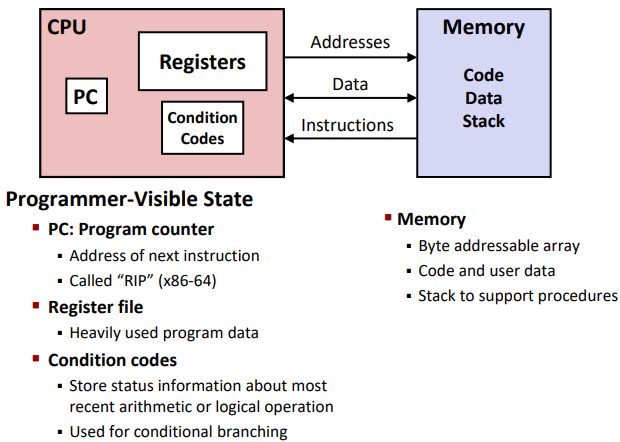
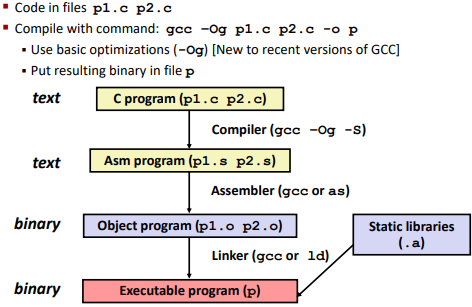
Turning C into Object Code
Ex:
1 | gcc -Og -S sum.c |
Use gcc to comply
-S: stop for the 1st step
-Og: what kind of optimization on code you choose (for debugging)
-O1: a lot of optimization( pretty hard to understand)
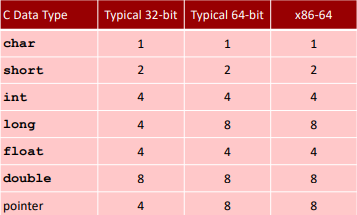
Data Types
| C | Data Type | assembly suffix | byte |
|---|---|---|---|
| char | byte | b | 1 |
| short | word | w | 2 |
| int | (two) word | l | 4 |
| char * | (two) word | l | 4 |
| float | single precision | s | 4 |
| double | bio-precision | l | 8 |
Disassembly(反汇编)
Ex:
1 | gcc -Og -S sum.c -o sum |
sum is a binary file(to disassembly the origin function)
Registers
x86-64 Integer Registers:

%rax(%eax) reserves the function’s return value.
$eip stands for instruction register and can not be changed. (Not in the picture)%rsp(%esp): stack pointer.
%rbp(%ebp): base pointer.Note: (the stack’s in memory top has lower address) (See more in the Procedures)
1 | pushl %ebp #equal to |
IA32 Registers:
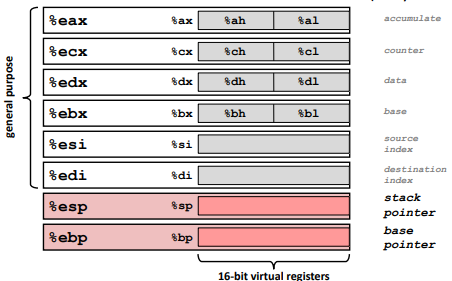
Just a legacy thing.
Move
1 | movq Source,Dest |

Operand types showing above,
Ex: (Understanding Swap())
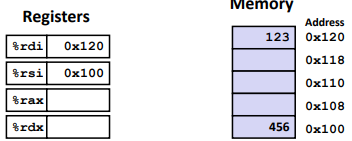
1 | swap: |
Addressing Modes
Simple Memory Addressing Modes
- Normal (R) Mem[Reg[R]]
- Register R specifies memory address
Aha! Pointer dereferencing in C
- Register R specifies memory address
1 | movq (%rcx),%rax |
- Displacement D(R) Mem[Reg[R]+D]
- Register R specifies start of memory region
Constant displacement D specifies offset
- Register R specifies start of memory region
1 | movq 8(%rbp),%rdx |
Complete Memory Addressing Modes
- Most General Form D(Rb,Ri,S) Mem[Reg[Rb]+S*Reg[Ri]+ D]
- ▪ D: Constant “displacement” 1, 2, or 4 bytes
▪ Rb: Base register: Any of 16 integer registers
▪ Ri: Index register: Any, except for %rsp
▪ S: Scale: 1, 2, 4, or 8 (why these numbers?)
- ▪ D: Constant “displacement” 1, 2, or 4 bytes
- Special Cases
- (Rb,Ri) Mem[Reg[Rb]+Reg[Ri]]
D(Rb,Ri) Mem[Reg[Rb]+Reg[Ri]+D]
(Rb,Ri,S) Mem[Reg[Rb]+S*Reg[Ri]]
- (Rb,Ri) Mem[Reg[Rb]+Reg[Ri]]
Ex. (Addressing Modes)

Arithmetic & logical operations
Address Computation Instruction
1 | leaq Src, Dst |
Src is address mode expression
Set Dst to address denoted by expressionUses: (Actually similar to move op)
▪ Computing addresses without a memory reference
▪ E.g., translation of p = &x[i];
▪ Computing arithmetic expressions of the form x + k*y
▪ k = 1, 2, 4, or 8
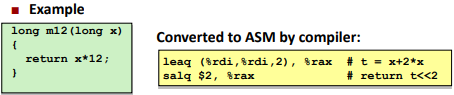
Difference from mov: (example)
1 | mov 1(%eax),%ebx |
Some Arithmetic Operations
Two Operand Instructions: (src=source)
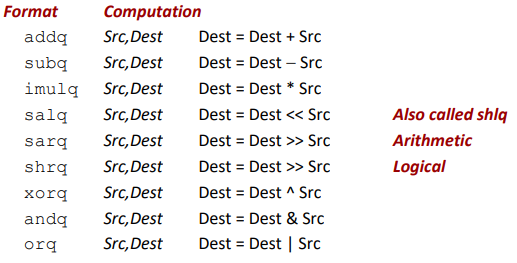
Watch out for argument order! Src,Dest
(Warning: Intel docs use “op Dest,Src”)
No distinction between signed and unsigned int (why?)
One Operand Instructions: (See book for more instructions)
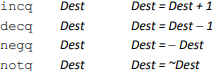
Ex.
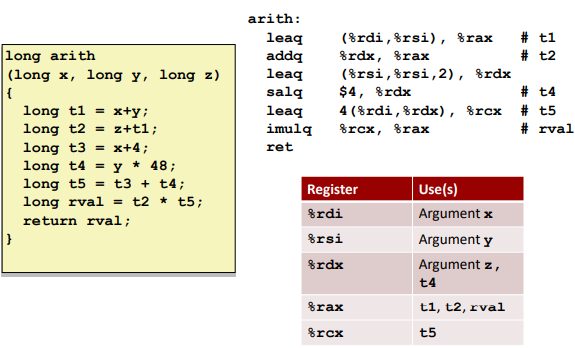
Control
Control: Condition codes

Compare Instruction:
1 | cmpq Src2,Src1 # Src1 - Src2 |
Test Instruction:
1 | testq Src2,Src1 # Src1 & Src2 |
Those instructions doesn’t change the value of registers.
SetX Instructions:
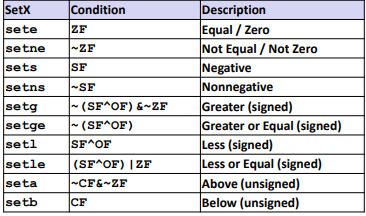
Help to change bit level values(t low-order byte of destination) for arithmetic.
Ex.
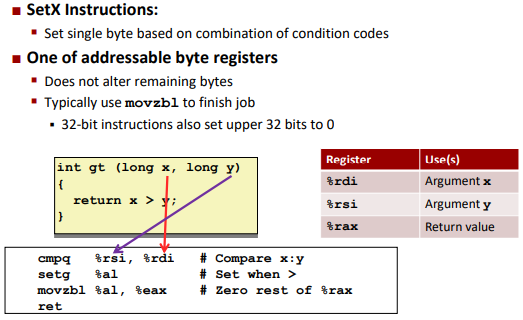
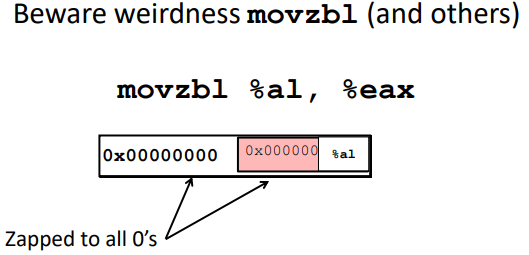
Note: (Intel x86 machine sets the upper bits to zeros implicitly)
![]()
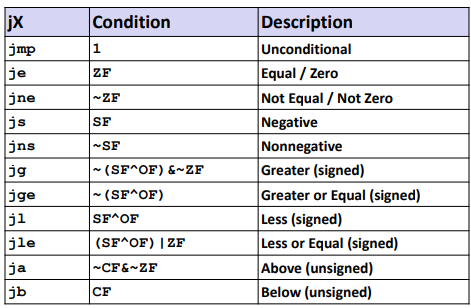
Conditional branches
Jumping
1 | jmp .L1 #address |
Ex.
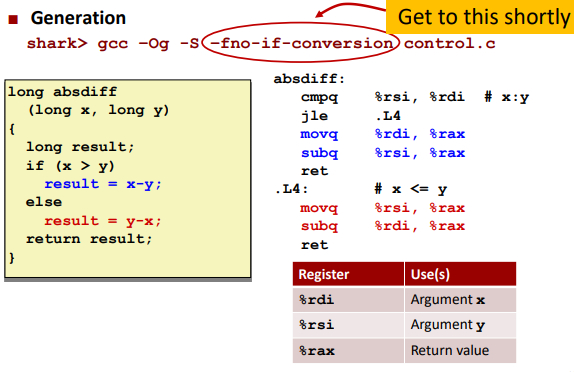
It’s behavior is just like to “goto” statement in C.
Condition move: (if the instruction is simple, calculate it first and then judge)

Loops
“Do-While” Loop Example: (it’s not often used)

While Loop Example: (there is an initial test)

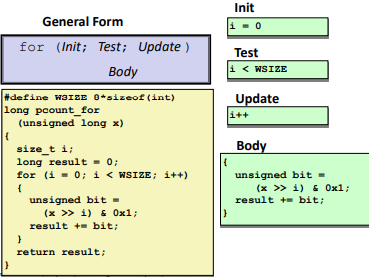
“For” Loop Form: (can be converted into other 2 kinds of loops)
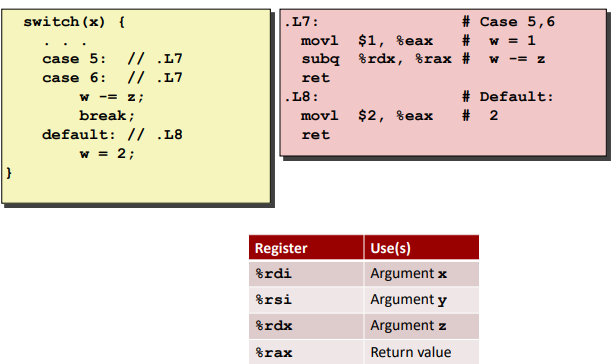
Switch Statements
Ex. (use “break” to end early)

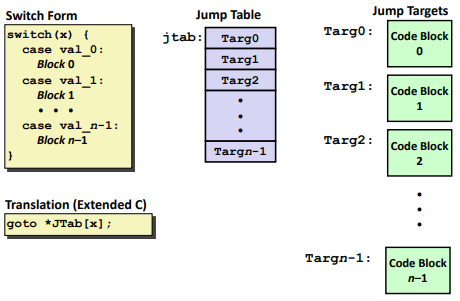
Jump Table Structure: (Avoid to step though all the codes)
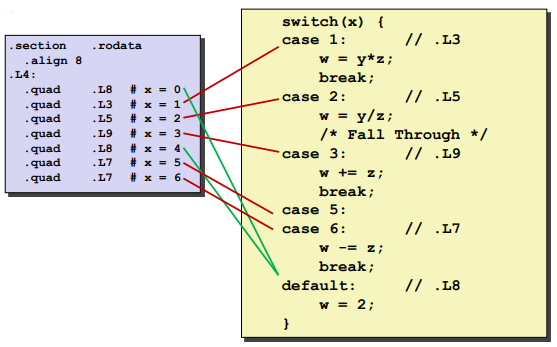
Ex:

ja: jump above. (x>6 and x<0 will jump to default case)
jmp: goto jump table.quad: state that need a 8byte value here.
Jump table:
![]()
Code Blocks (x == 2, x == 3): (Note that the block doesn’t have some orders)
![]()
Code Blocks (x == 5, x == 6, default):
![]()

Summary:

Procedures
Function, method, procedure….
Mechanisms

Stack Structure
x86-64 Stack:
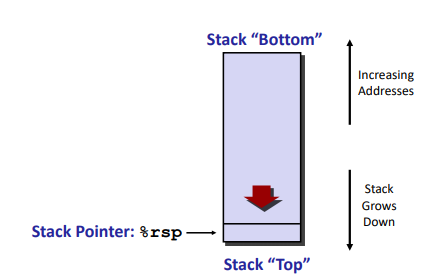
Note: the direction are controversial maybe.
(The memory doesn’t change, only the value of %rsp)
1 | #the %ebp contains a value to save |
1 | leave #equal to |
Ex.
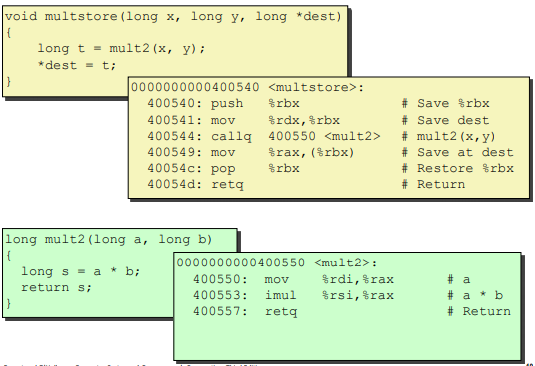
A example: Here. (Chinese)
Calling Conventions
Passing control
1 | callq address <func_name> |
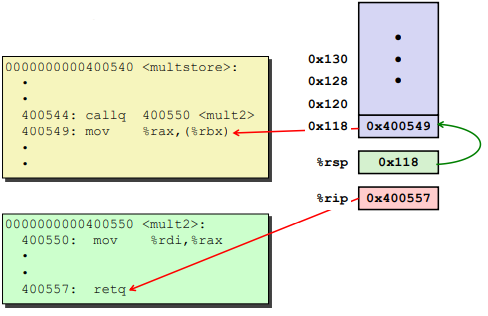
Passing data
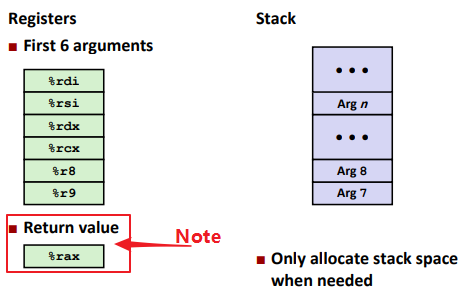
Ex.

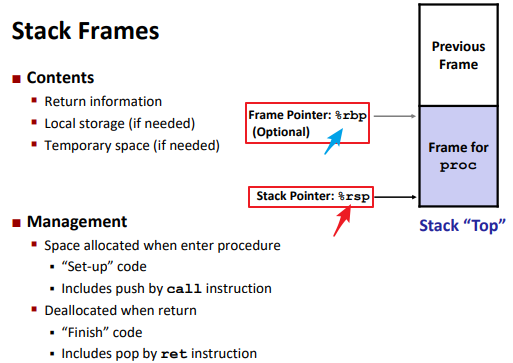
Managing local data
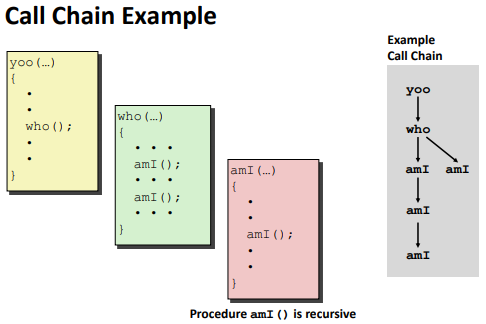
Call Chain:
Stack Frames: (%rsp)
Example see in the slides.(Also the Illustration of Recursion part)
Data
Arrays
Easy.
Ex.

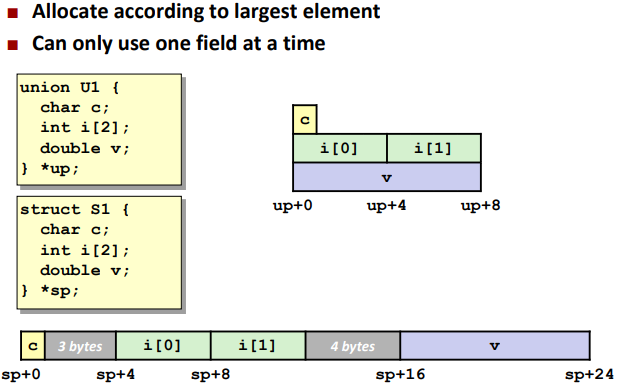
Structures
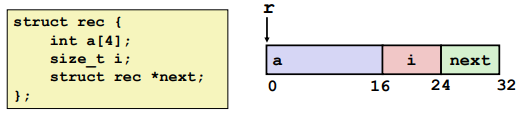
Alignment: (对齐)
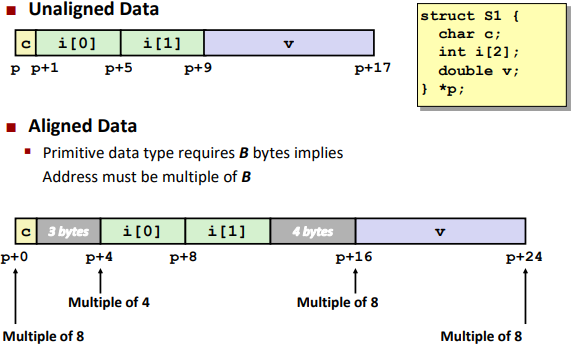
Alignment is depending on the next data type.
![]()
Save space:
![]()

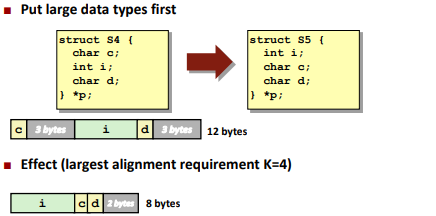
Floating Point
Similarly.
Advanced Topics
Memory Layout
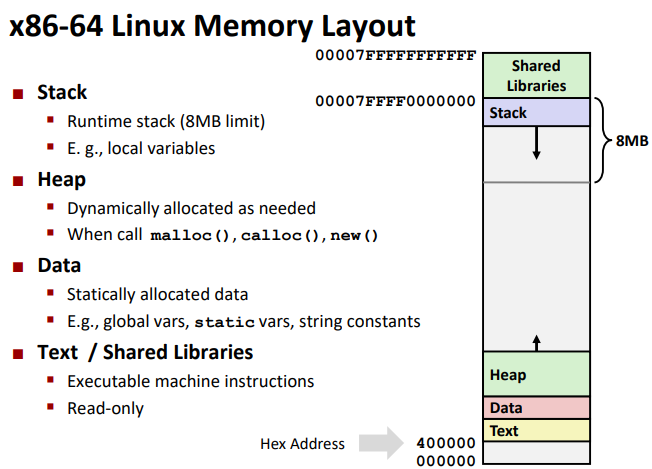
Buffer Overflow
when exceeding the memory size allocated for an array.
String Library Code:

Ex; (Buffer Overflow Disassembly)
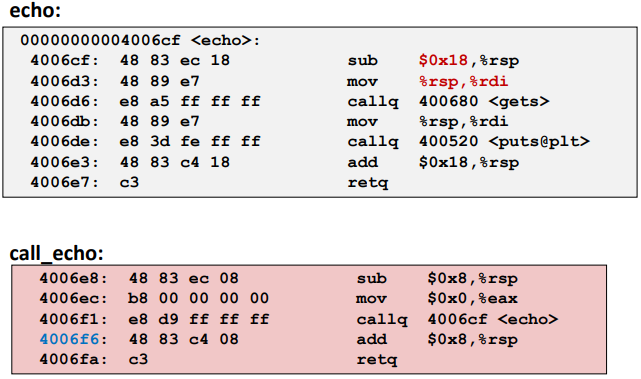
Things can go wrong without a crash.
For string, note that there is a byte order.
Avoid Overflow Vulnerabilities in Code:
1 | fgets(buf, 4, stdin); |
System-Level Protections can help.
- Randomized stack offsets
Nonexecutable code segments.
Stack Canaries can help.
- Idea
▪ Place special value (“canary”) on stack just beyond buffer
▪ Check for corruption before exiting function- GCC Implementation
▪ -fstack-protector
▪ Now the default (disabled earlier)
Unions
Byte Ordering Example: (only ordered inside a single data)
Code Optimization
Generally Useful Optimizations
Optimizations that you or the compiler should do regardless of processor / compiler.
Code Motion
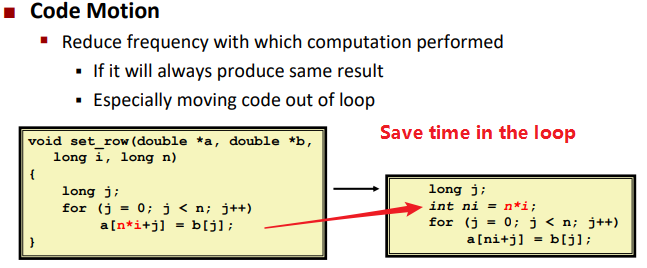
Reduction in Strength

Share Common Subexpressions

Optimization Example: Bubblesort

Optimization Blockers
Procedure calls

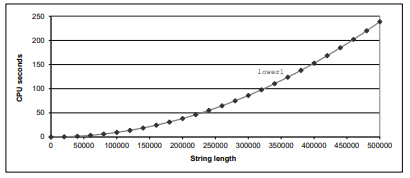
Note the function
strlen(), it will be running the whole time and make the program perform badly.($O(n^2)$)![]()
Memory aliasing

Removing Aliasing: (don’t use reference unless you have to)

Exploiting Instruction-Level Parallelism

Cycles Per Element (CPE)
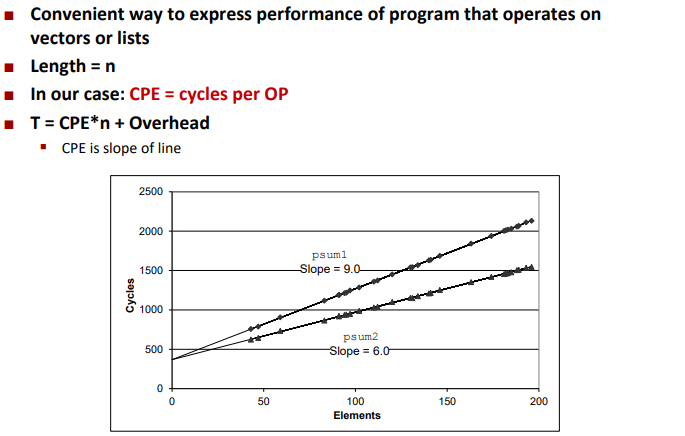
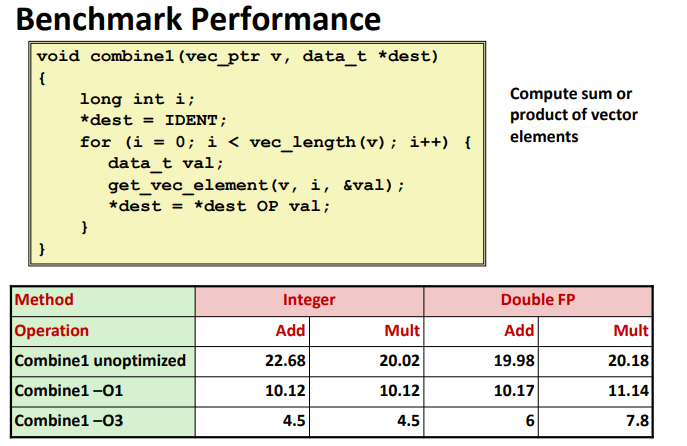
Benchmark Performance:
Loop Unrolling

Multiple Accumulators
Loop Unrolling with Separate Accumulators (2x2):
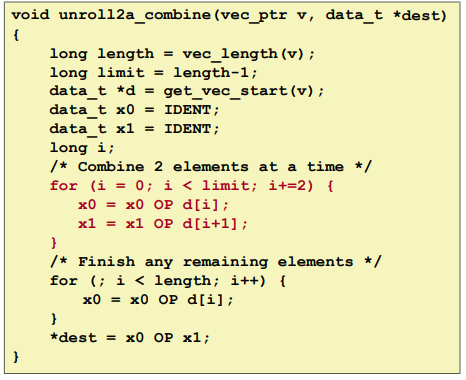
Summary:

The Memory Hierarchy
Storage technologies and trends
Random-Access Memory(RAM).
RAM comes in two varieties:
▪ SRAM (Static RAM)
▪ DRAM (Dynamic RAM)
Disk.
Solid State Disks(SSD).
Bus.(总线)
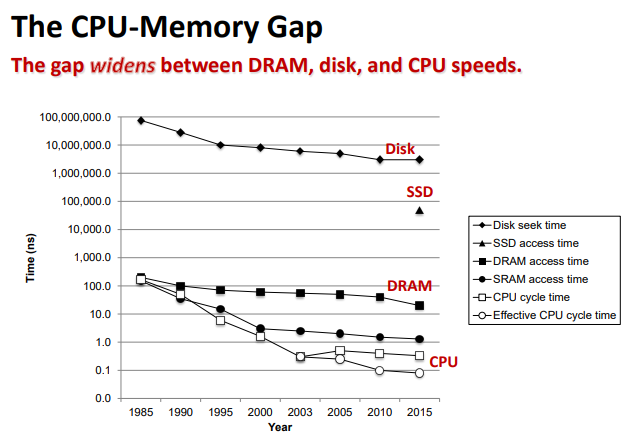
Locality of reference

Caching in the memory hierarchy
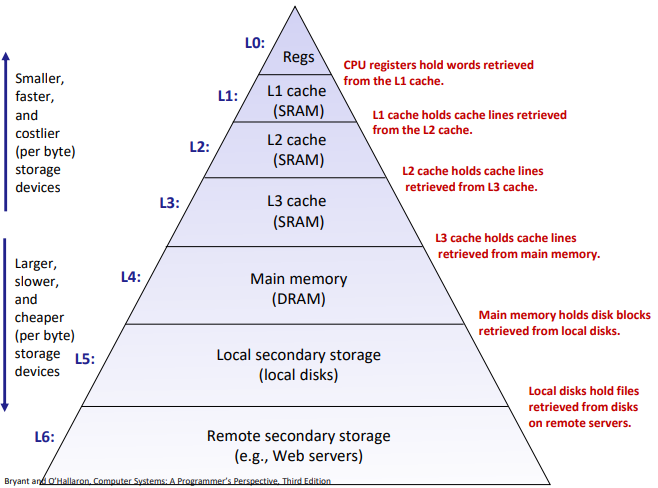
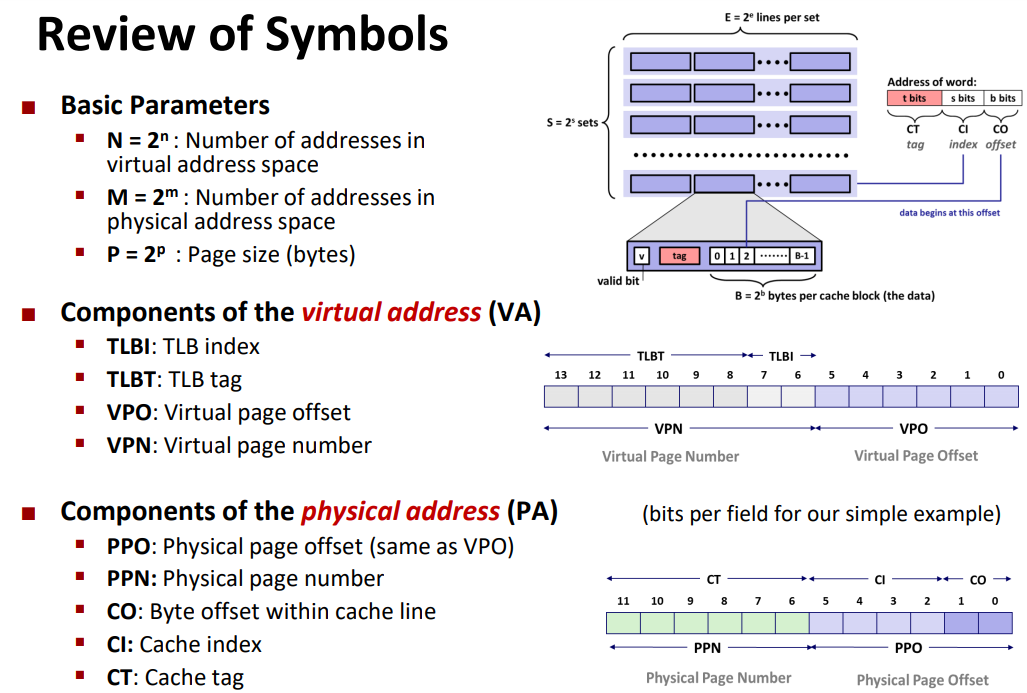
General Cache Concepts:
See in the slides.
3 Types of Cache Misses:

For conflict miss, each block represent one specific next level cache block. (Can’t use to save other values)
Cache Memories
Cache organization and operation
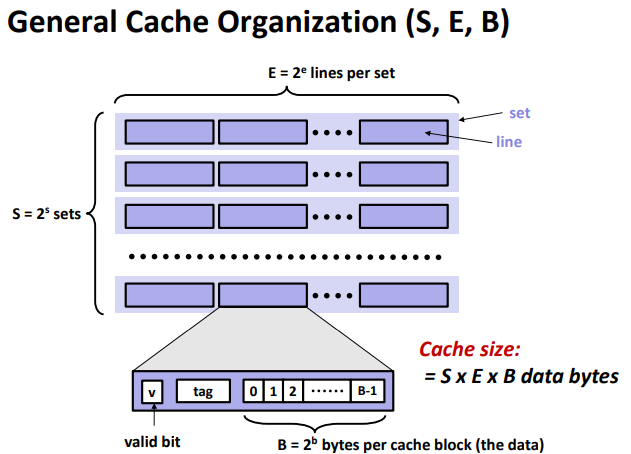
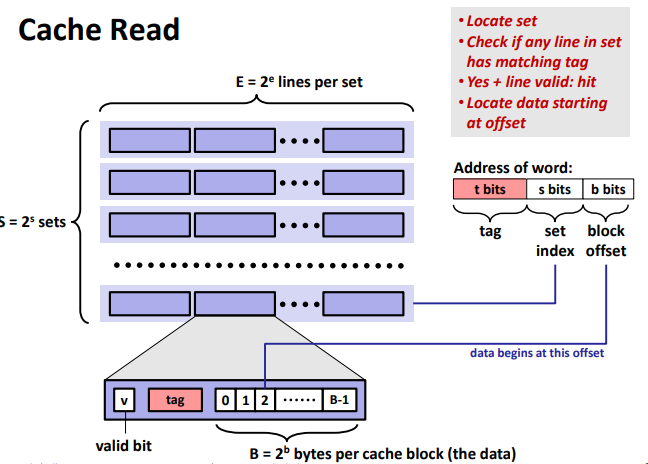
Direct Mapped Cache (E = 1): (One line per set. Assume: cache block size B=8 bytes)
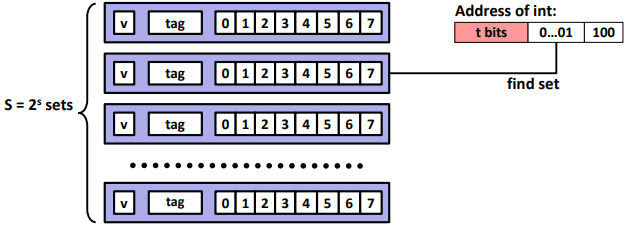
• Locate set
• Check if any line in sethas matching tag
• Yes + line valid: hit
• Locate data starting at offsetIf tag doesn’t match (= miss): old line is evicted and replaced
Ex. (Direct-Mapped Cache Simulation)

E-way Set Associative Cache (Here: E = 2):
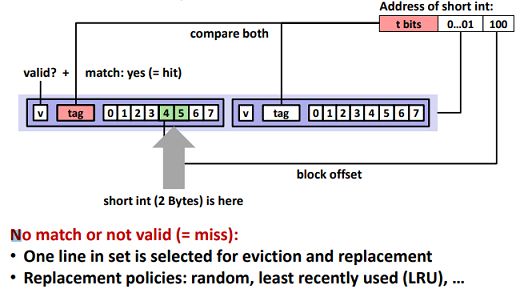
Ex. (2-Way Set Associative Cache Simulation)

What about writes?
![]()

Performance impact of caches
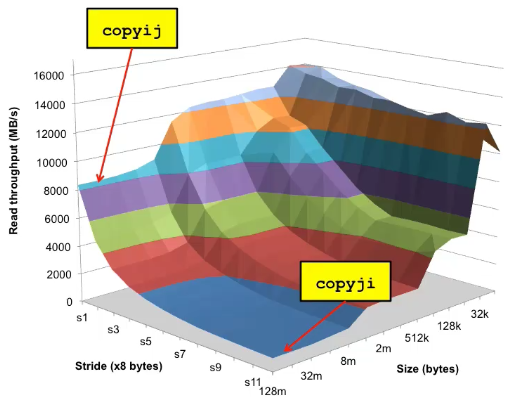
The memory mountain
Read throughput (read bandwidth)
▪ Number of bytes read from memory per second (MB/s)
Memory mountain: Measured read throughput as a function of spatial and temporal locality.
▪ Compact way to characterize memory system performance.
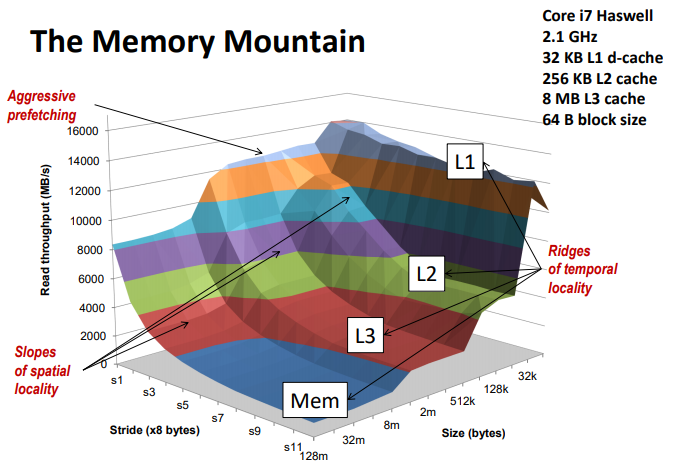
Rearranging loops to improve spatial locality
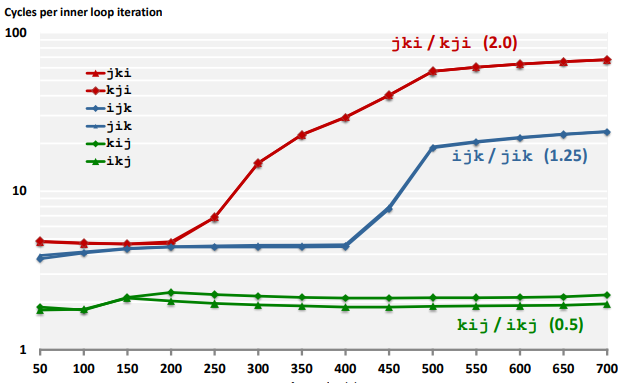
Ex. (Matrix Multiply Performance)

Using blocking to improve temporal locality
See in the slides.
Linking
Ex. (Example C Program)

Programs are translated and linked using a compiler driver:
1 | linux> gcc -Og -o prog main.c sum.c |
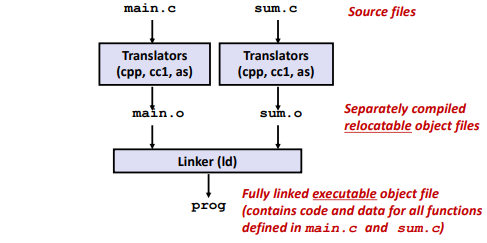
Why Linkers?
- Reason 1: Modularity
- Reason 2: Efficiency (time/space)
What Do Linkers Do?
- Step 1: Symbol resolution (During symbol resolution step, the linker associates each symbol reference
with exactly one symbol definition.) - Step 2: Relocation (Merges separate code and data sections into single sections)
Three Kinds of Object Files (Modules)
- Relocatable object file (.o file)
- Executable object file (a.out file)
- Shared object file (.so file)
Linker Symbols

just like: public, friend, and private.
Program symbols are either strong or weak:
- Strong: procedures and initialized globals
- Weak: uninitialized globals
Or ones declared with specifier extern
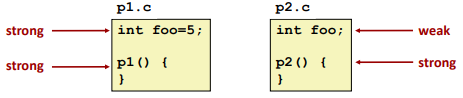
Rule 1: Multiple strong symbols are not allowed
- Each item can be defined only once
Otherwise: Linker errorRule 2: Given a strong symbol and multiple weak symbols, choose the strong symbol
- References to the weak symbol resolve to the strong symbol
Rule 3: If there are multiple weak symbols, pick an arbitrary
one
- Can override this with gcc –fno-common
Ex. (Linker Puzzles)

Global Variables: (caution)
- Avoid if you can
- Otherwise
§ Use static if you can
§ Initialize if you define a global variable
§ Use extern if you reference an external global variable§ Treated as weak symbol § But also causes linker error if not defined in some file
Shared Library (Modern Solution)
Case study: Library interpositioning


ECF(Exceptional Control Flow)
Exceptions & Processes
Exceptional Control Flow

Exceptions
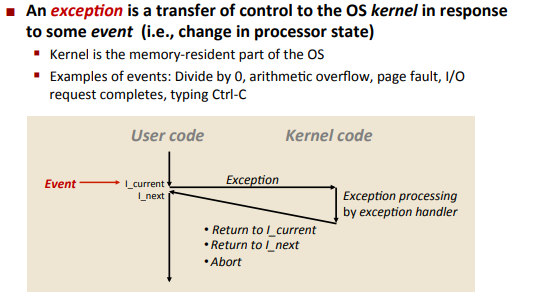
Interrupts(Asynchronous Exceptions)

Synchronous Exceptions

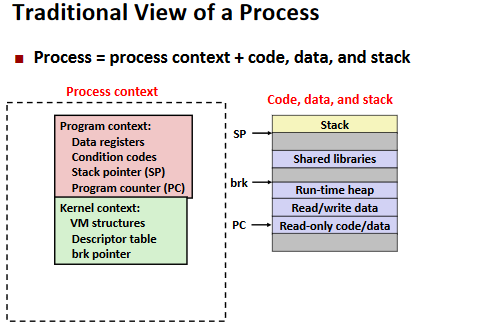
Processes

Process Control
Obtaining Process IDs
pid_t getpid(void)
- Returns PID of current process
pid_t getppid(void)
- Returns PID of parent process
Creating and Terminating Processes
void exit(int status)
terminated.
Convention: normal return status is 0, nonzero on error
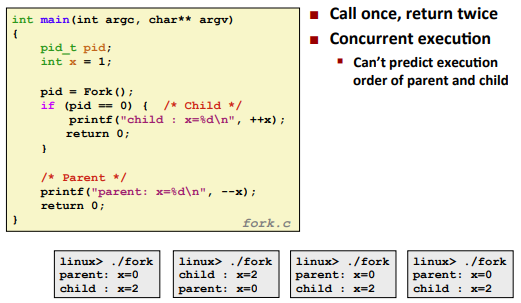
int fork(void)
Returns 0 to the child process, child’s PID to parent process。(called once, return twice)
Ex. (can’t predict the exact return value of fork)
![]()
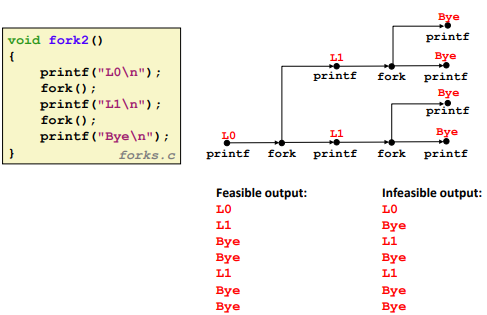
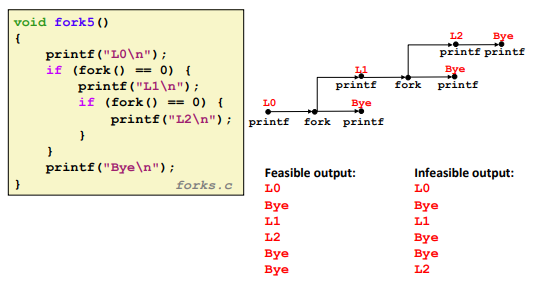
Two consecutive fork:
![]()
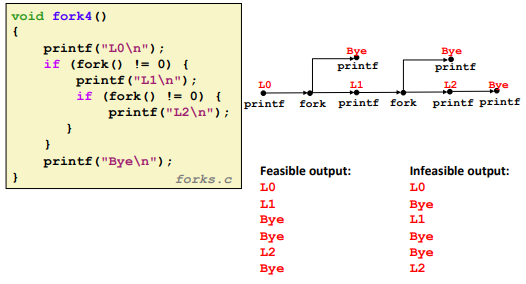
Nested forks in parent: (Similar)
![]()
![]()
int wait(int *child_status)
return
child’s PIDif succeed,-1otherwise.
Ex.
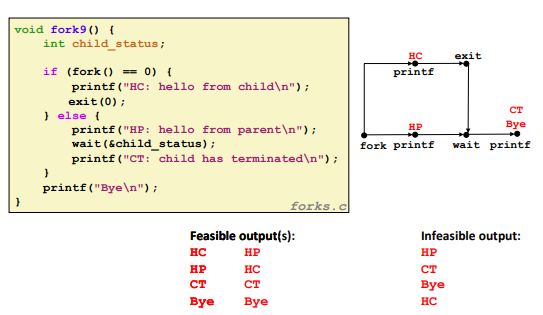
Ex. (fork + wait)
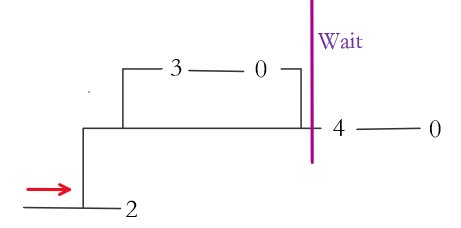
Note: (The processes will run parallelly unless some of them have to wait)
![]()
int execve(char *filename, char *argv[], char *envp[])
- never returns.
Signals & Nonlocal Jumps
setjmp
- use once, return twice
longjmp
- use once and never return
Virtual Memory
Concepts
Address spaces

Why Virtual Memory (VM)?
- Uses main memory efficiently
- Simplifies memory management
- Isolates address spaces
VM as a tool for caching
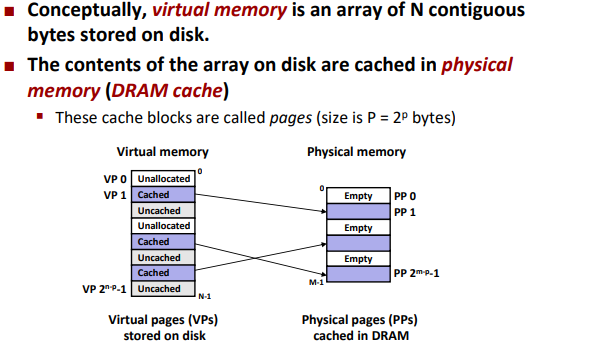
Enabling Data Structure: Page Table
A page table is an array of page table entries (PTEs) that maps virtual pages to physical pages.
▪ Per-process kernel data structure in DRAM
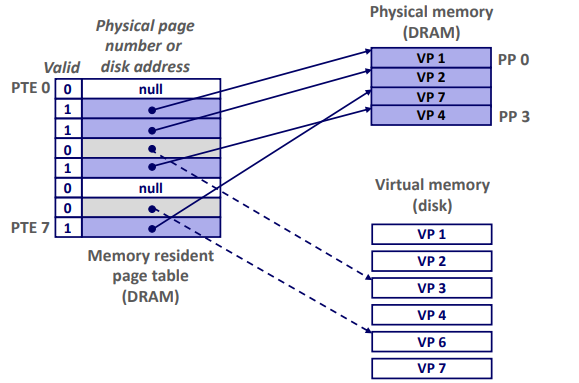
Page hit: reference to VM word that is in physical memory (DRAM cache hit)
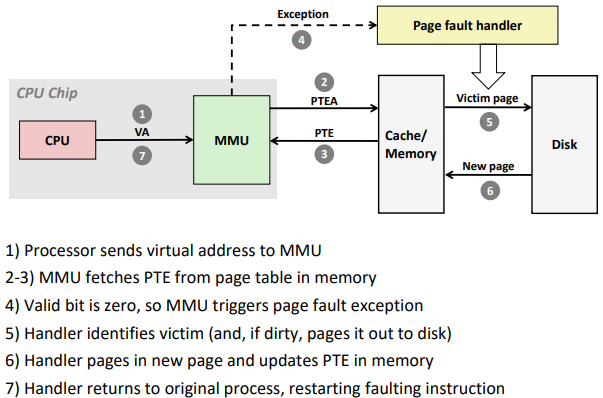
Page fault: reference to VM word that is not in physical memory (DRAM cache miss)
Handling Page Fault: Page miss causes page fault (an exception)
Locality to the Rescue Again!

VM as a tool for memory management
Key idea: each process has its own virtual address space
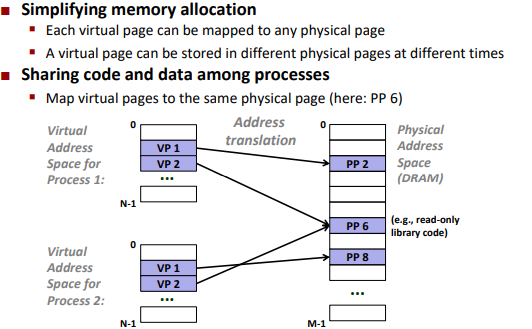
VM as a tool for memory protection
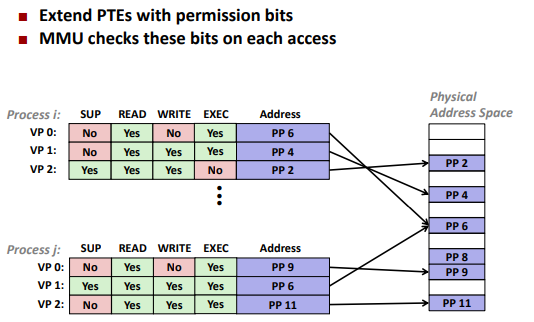
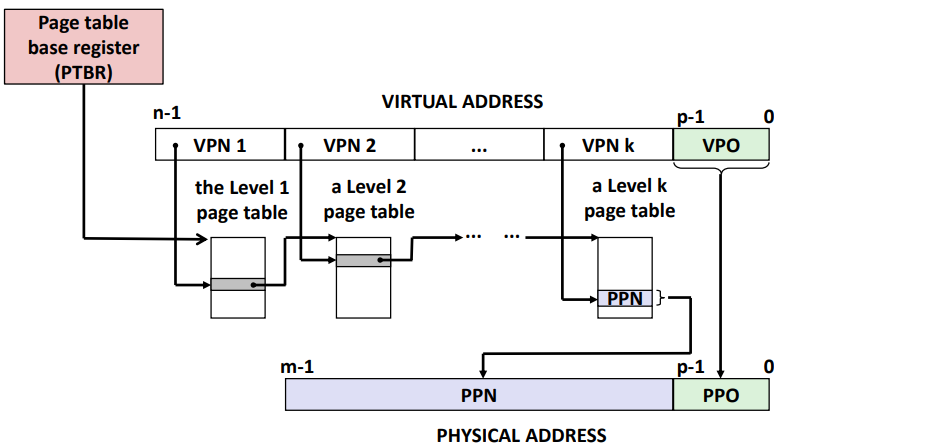
Address translation
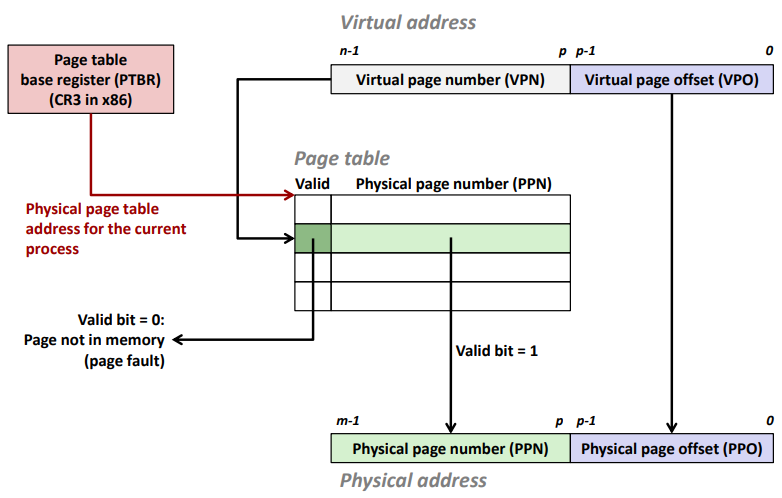
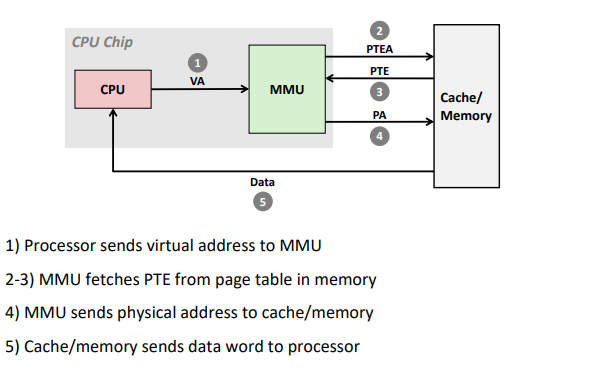
Address Translation: Page Hit
Address Translation: Page Fault
Integrating VM and Cache
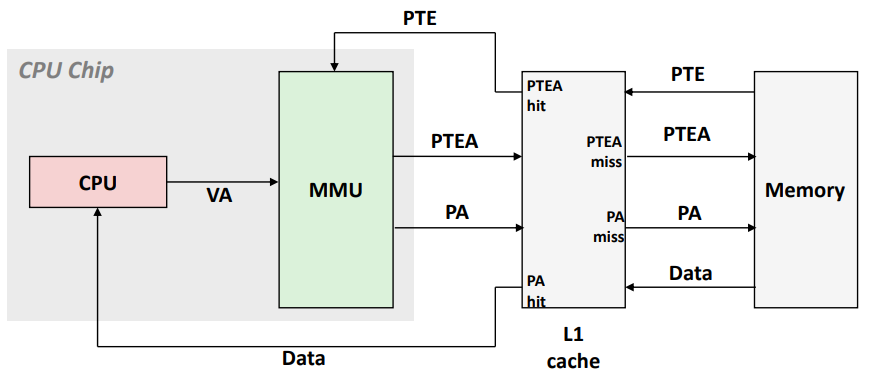
VA: virtual address, PA: physical address, PTE: page table entry, PTEA = PTE address.

Multi-Level Page Tables

A Two-Level Page Table Hierarchy
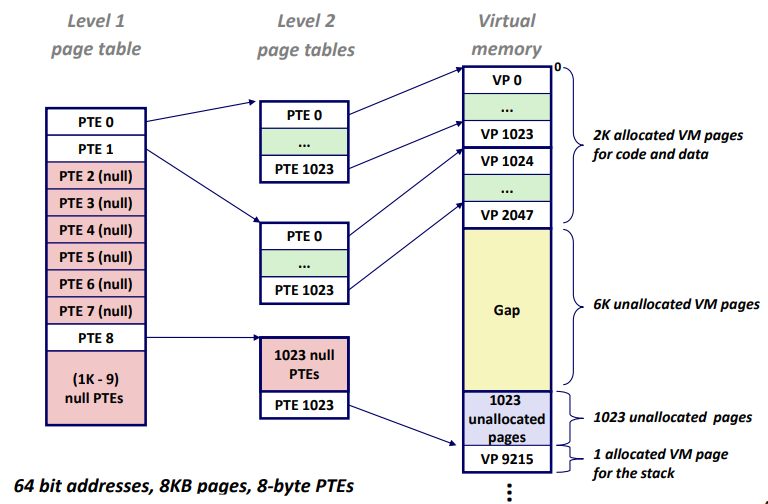
Translating with a k-level Page Table
Systems
Case study: Core i7/Linux memory system
None.
Some page were marked to be protected by core so that the user can’t alter.
There are L1~L4 page tables.
Trick: VPO=PPO=Physical Address. (The lower bits of Block address)
Memory mapping
The address translation is always running.
Dynamic Memory Allocation
Basic
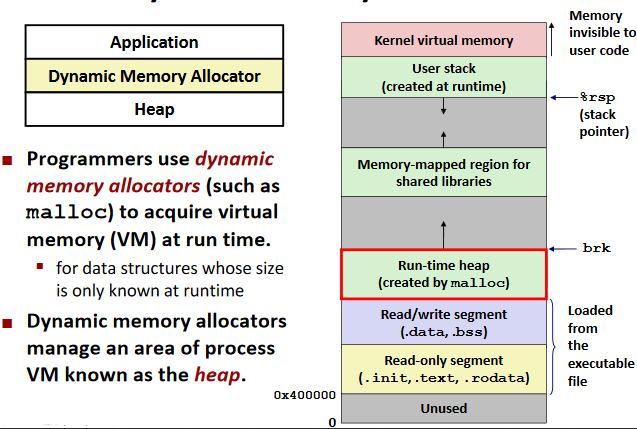
void* malloc(size_t size)
- get a block by given size
void free(void *p)
- free the block at the address
calloc: version of malloc that initializes block to 0
realloc: change the size of it
sbrk: control allocators to grow or shrink the heap
Throughout: number of complete requests per unit time.
5000 malloc + 5000 free in 10 sec, then throughout will be 1000 operation/sec.
Peak Memory Utilization:
aggregate payload $P_k$.
Current heap size $H_k$
- $Uk=max{i\leq k}P_i/H_k$
Can cause by fragmentation.(internal or external)
![]()
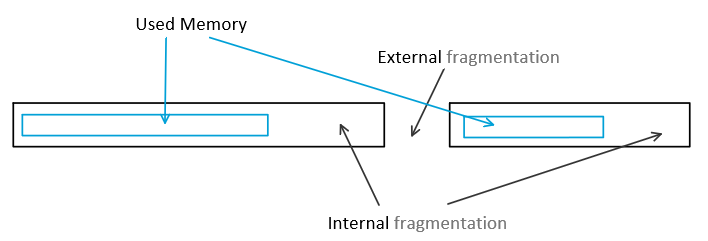
Advanced
Explicit free lists
Keeping Track of Free Blocks:
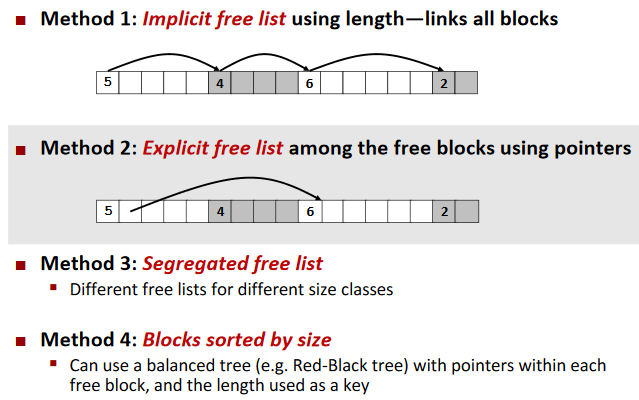
Explicit free lists:
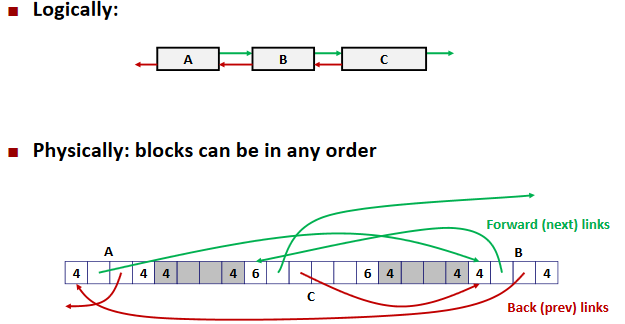
Freeing With Explicit Free Lists:

Often use BBST to manage the allocated memory.
Explicit List Summary:

Segregated free lists
Each size class of blocks has its own free list.
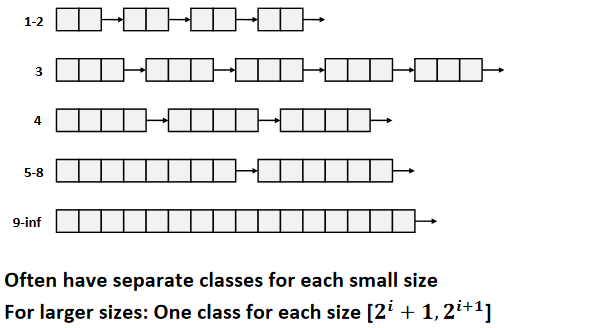


Garbage collection
Garbage collection :automatic reclamation of heap-allocated storage—application never has to explicitly free memory.
Common in many dynamic languages:
▪Python, Ruby, Java, Perl, ML, Lisp, Mathematica
The tech is still ongoing.
![]()

Graph:
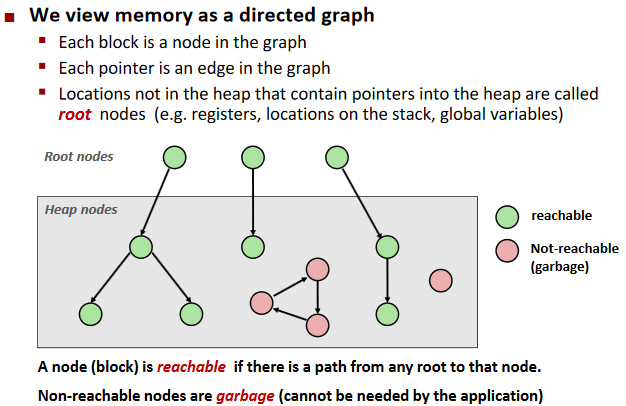
Mark and Sweep Collecting:
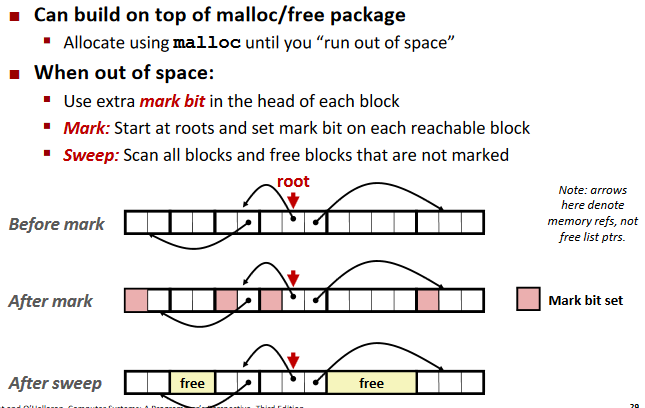
Assumptions For a Simple Implementation:

Mark and Sweep (cont.)

Memory-related perils and pitfalls
Dereferencing Bad Pointers
The classic scanf bug:

Reading Uninitialized Memory
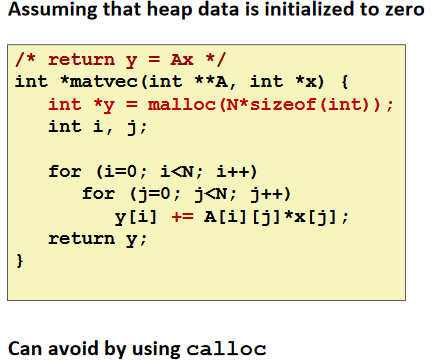
Overwriting Memory

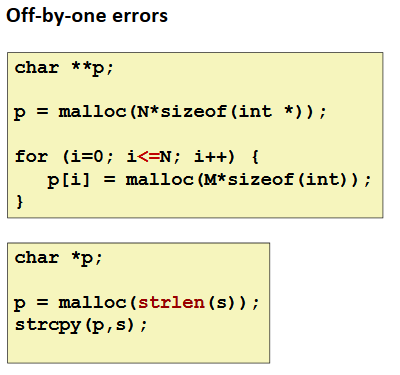
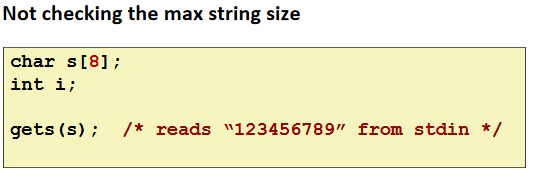

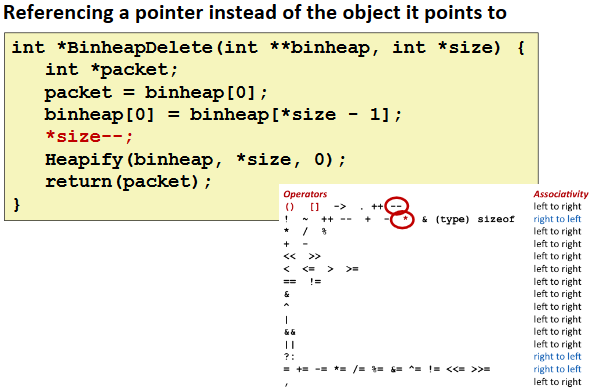
Referencing Nonexistent Variables

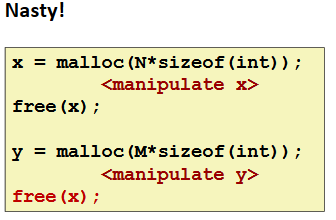
Freeing Blocks Multiple Times
Referencing Freed Blocks
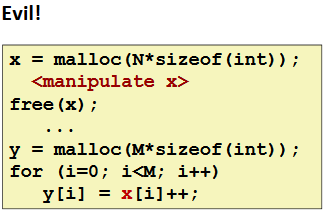
Failing to Free Blocks (Memory Leaks)
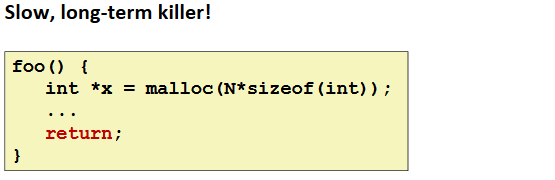
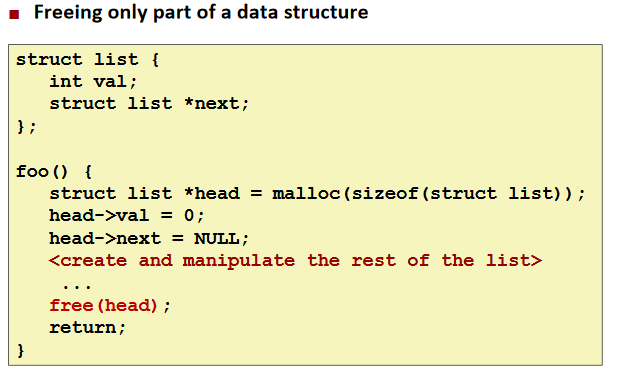
Ex.


System-Level I/O
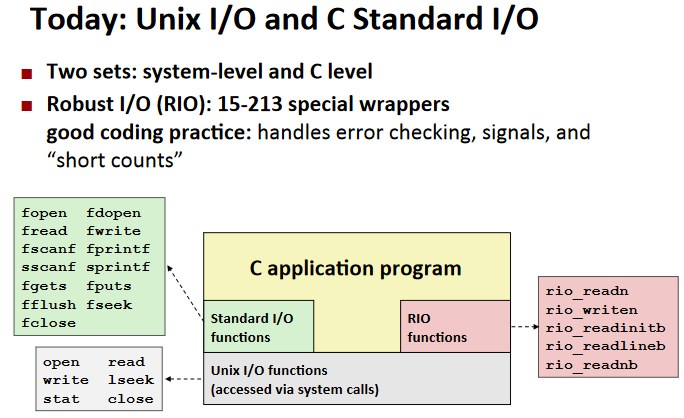
Unix I/O

Unix I/O Overview:

File Types

Regular Files

Windows type
\r\nactually relates to the usage of typewriter.
Pathname
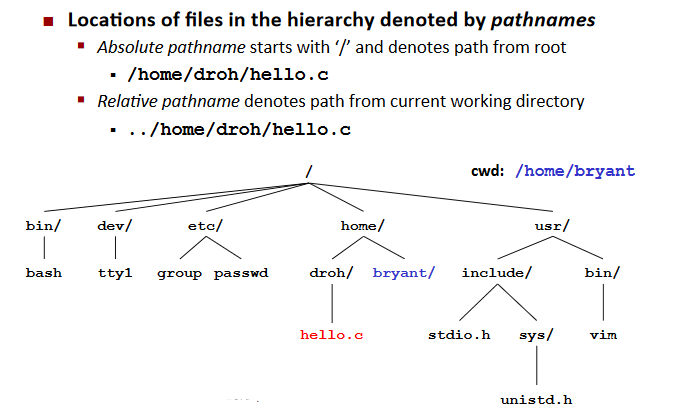
Opening Files
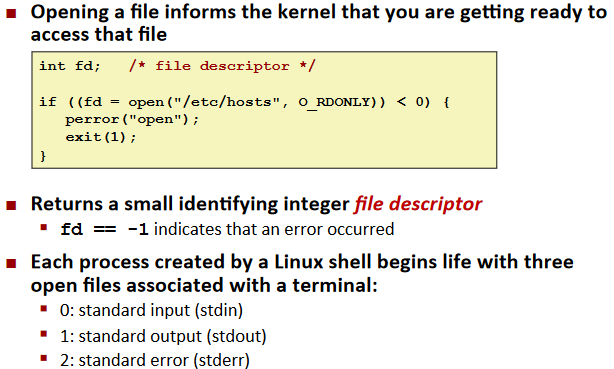
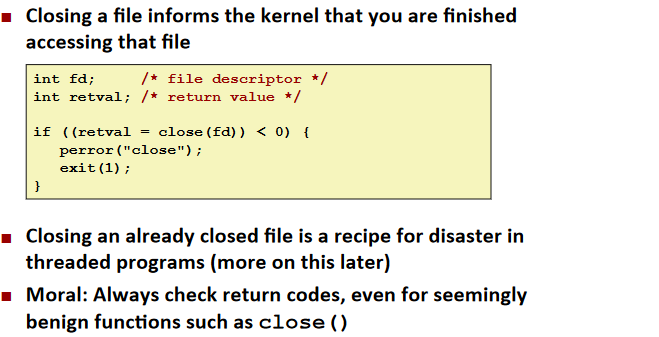
Closing Files
Reading Files

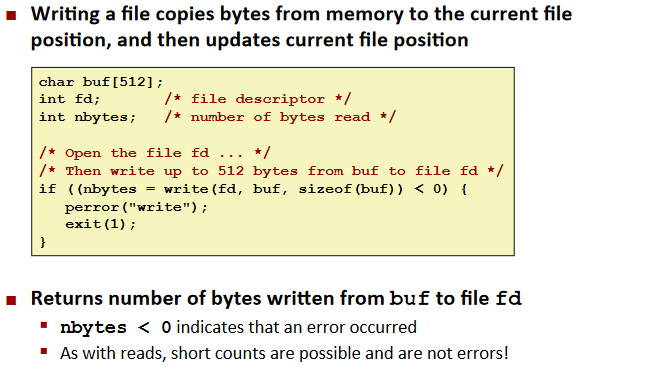
Writing Files
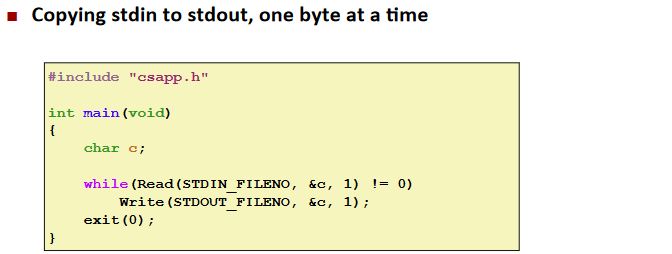
Ex. (sample)
Metadata. sharing, and redirection

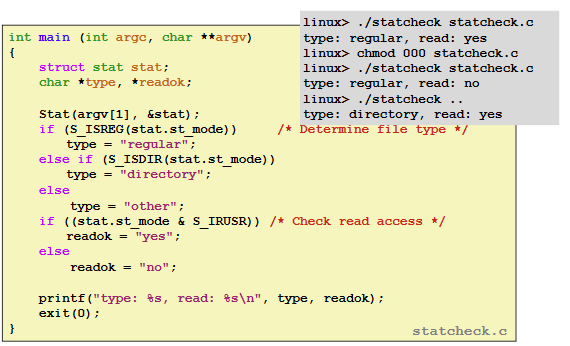
Ex. (Example of Accessing File Metadata)
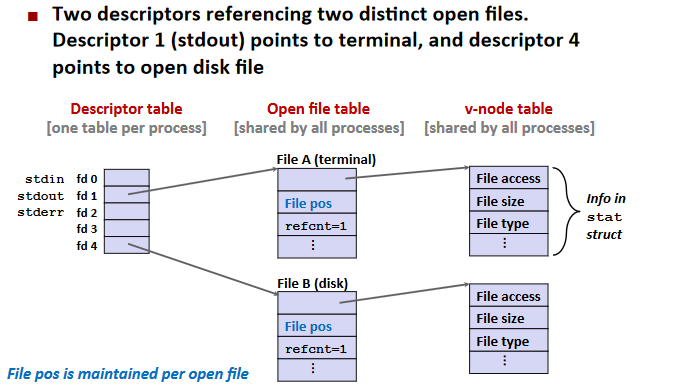
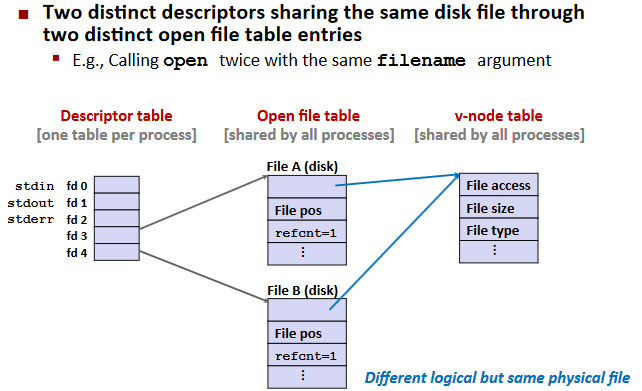
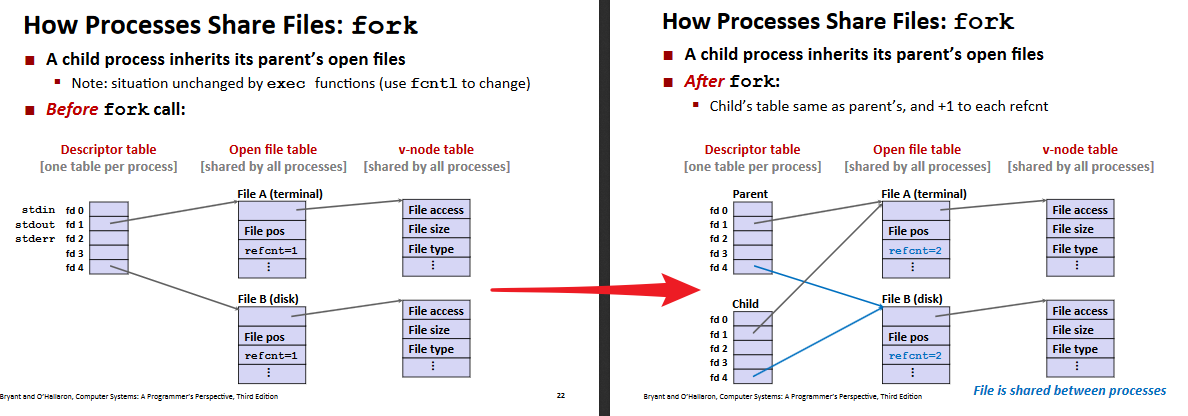
File Sharing
I/O Redirection
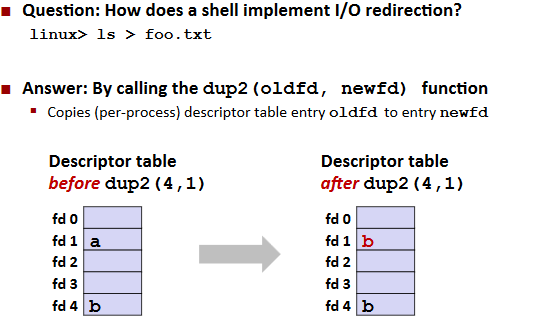
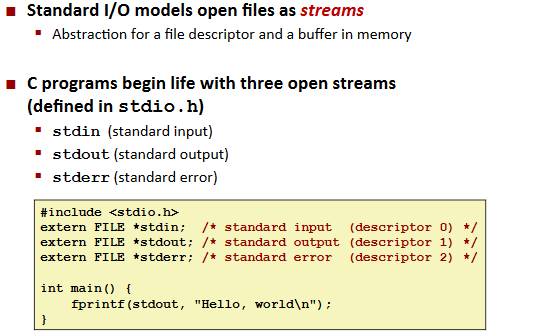
Standard I/O
Functions:

Std. I/O Streams:
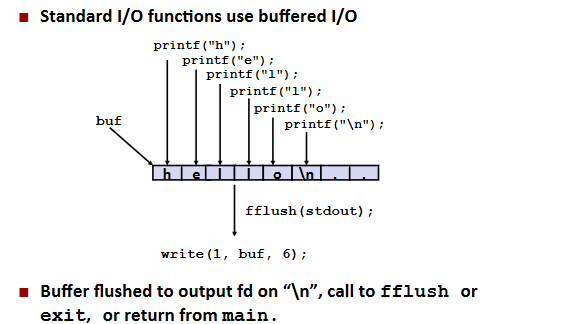
Buffering in Standard I/O:

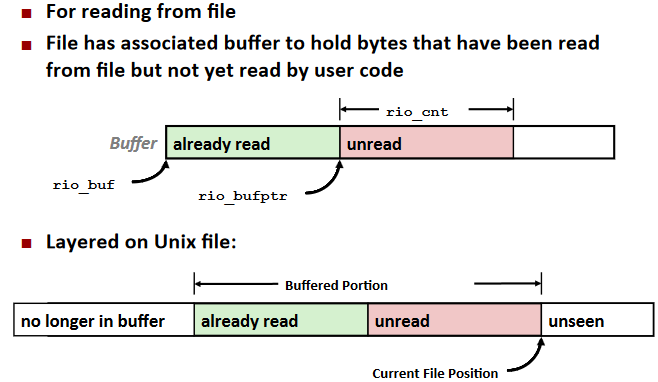
RIO(robust I/O) package

Buffered I/O: Implementation:
Closing remarks
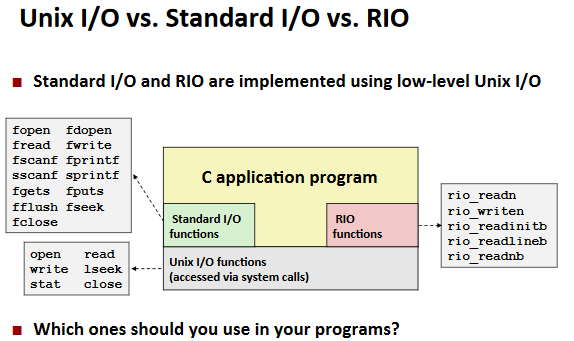
For more information:

Network Programing
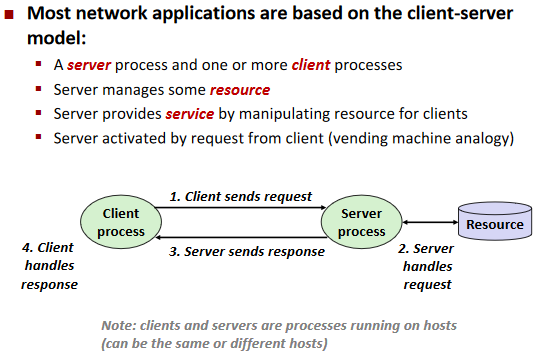
A Client-Server Transaction
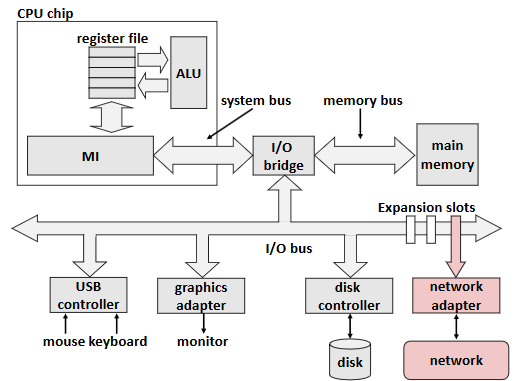
Computer Networks

Structure
Lowest Level: Ethernet Segment
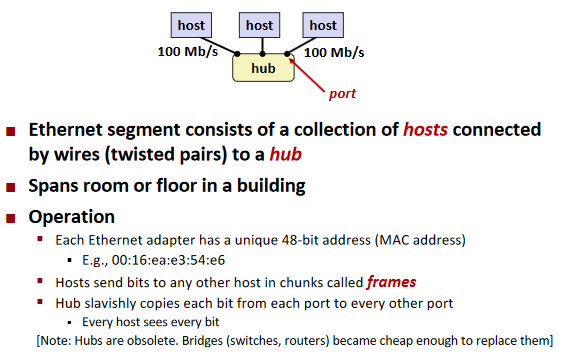
Broadcast mechanism.
Next Level: Bridged Ethernet Segment
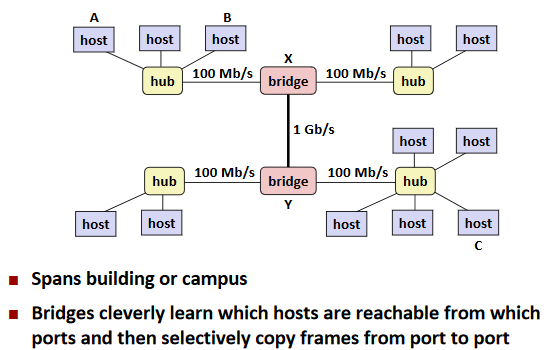
LAN: Local area network.
WLAN: Wireless local area network.
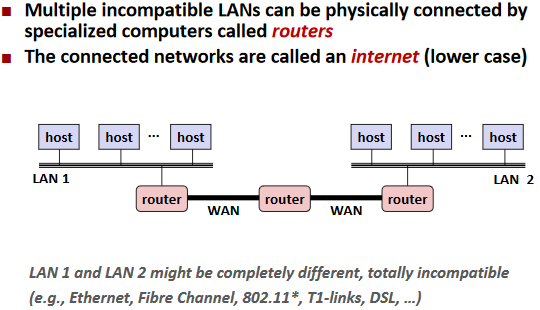
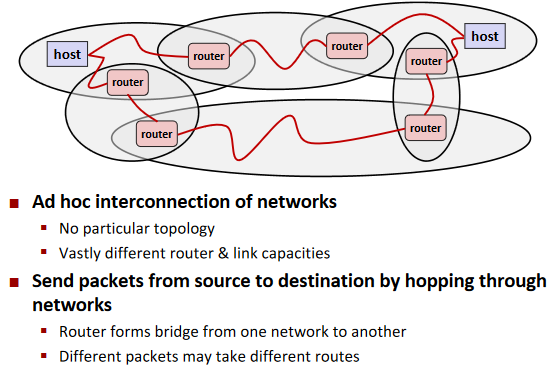
Next Level: internets
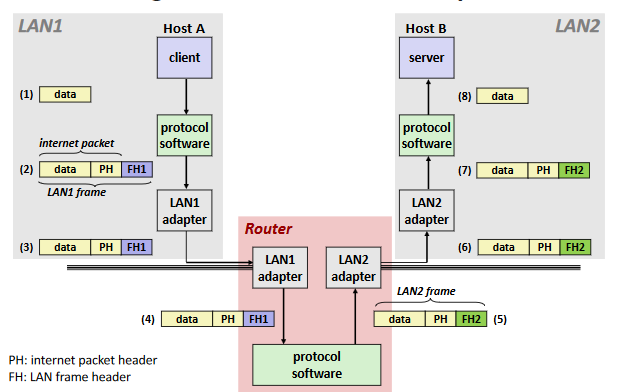
Transferring internet Data Via Encapsulation:
Global IP Internet

Internet Domain Name
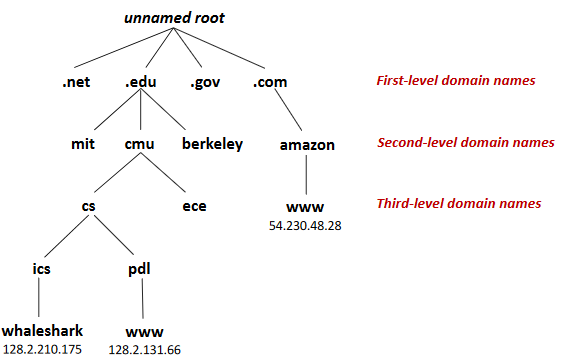
Domain Naming System (DNS)

can be multi-multi mapping.
Sockets
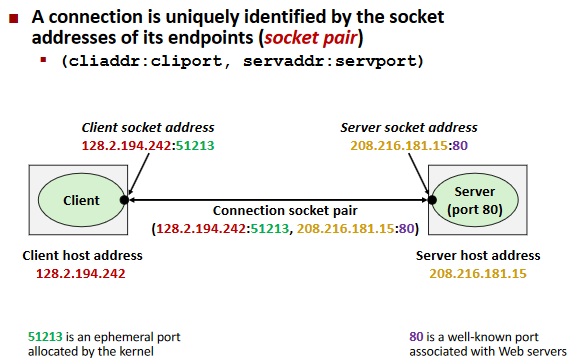
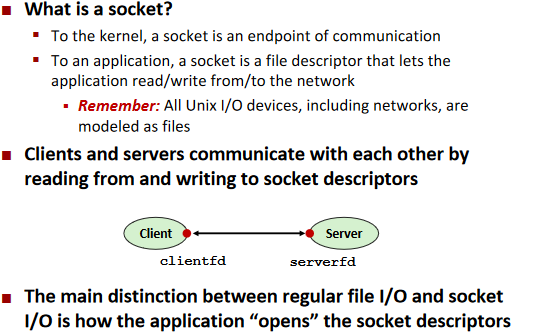


Socket Interface
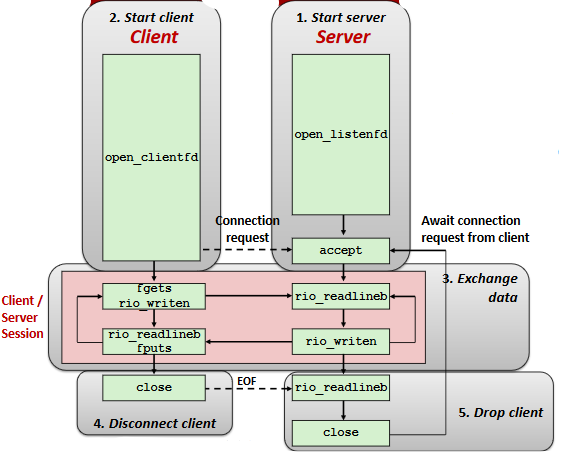
The advanced topic can be seen in the video and related slides.
Concurrent programming
The lecturer always says “good to see you”.

Situation Examples

Data Race:
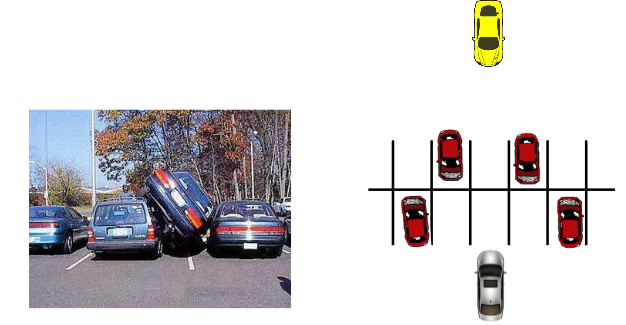
Deadlock:

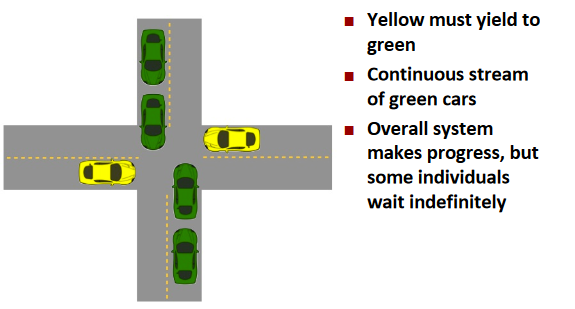
Starvation:

Iterative Servers
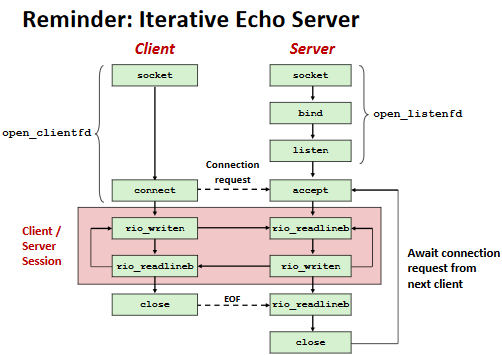
Iterative servers process one request at a time.
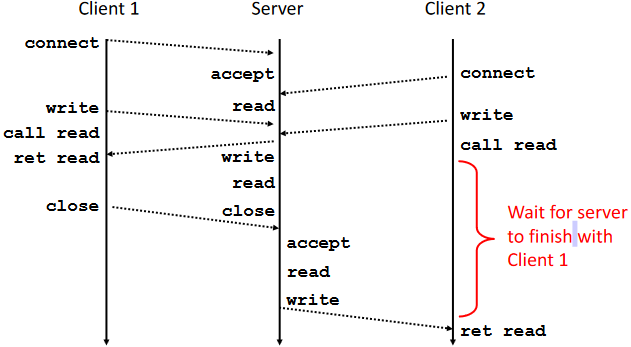
Fundamental Flaw of Iterative Servers: (example)
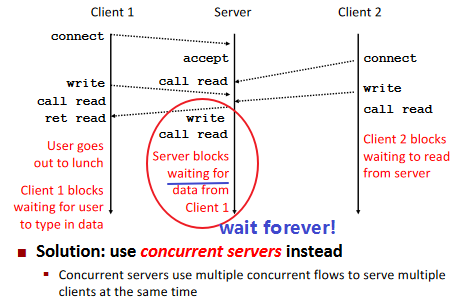
Writing Concurrent Servers
Approaches for Writing Concurrent Servers:

Approach 1: Process-based Servers(进程)
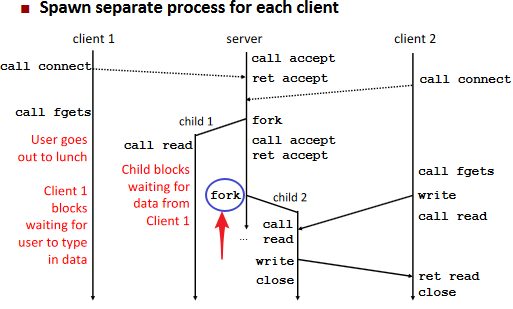
Approach 2: Event-based Servers

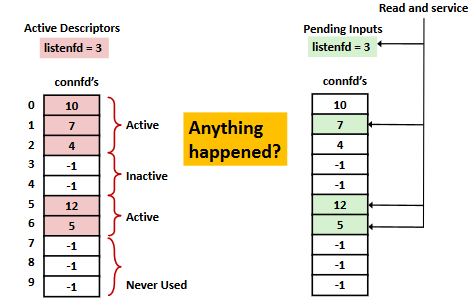
I/O Multiplexed Event Processing:
Approach 3: Thread-based Servers(线程)
Very similar to approach #1 (process-based)
…but using threads instead of processes
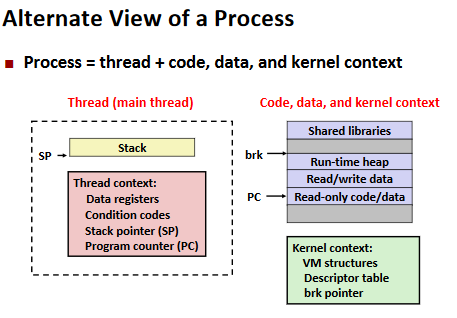

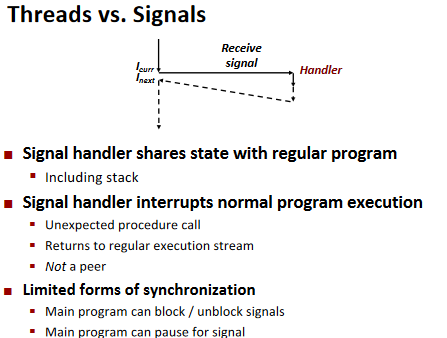
Summary: Approaches to Concurrency

Synchronization
Threads review
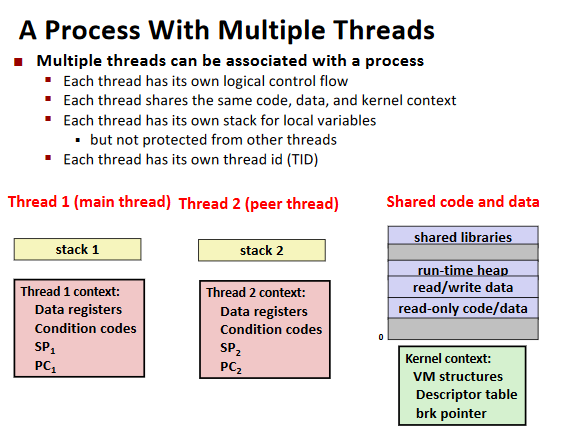
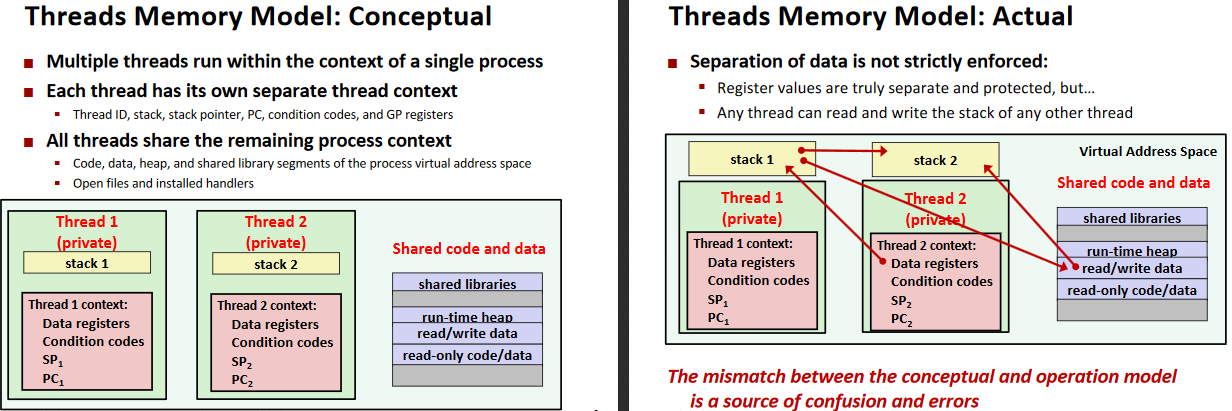
Sharing
Ex. (Example Program to Illustrate Sharing)

Mapping Variable Instances to Memory:

Ex.
![]()
Ex. (Shared Variable Analysis)
![]()


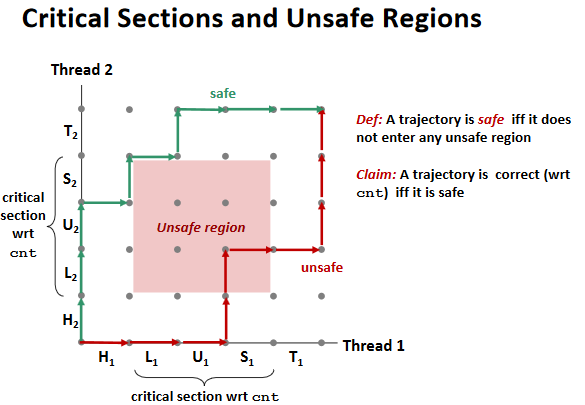
Mutual exclusion

Semaphores

Summary:

Using semaphores to schedule shared resources
Producer-consumer problem
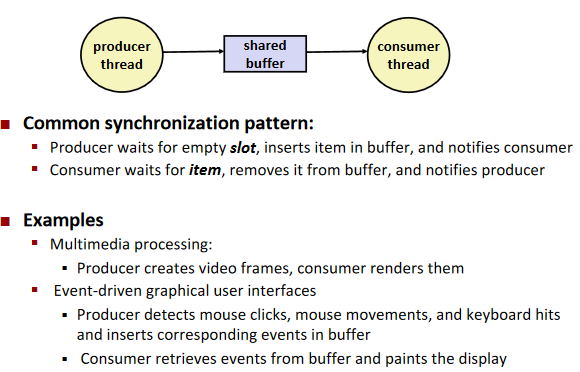
Note: limited buffer
Maintain two semaphores: full + empty
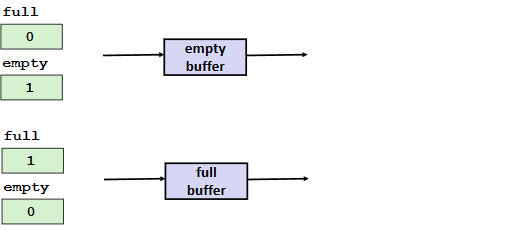
Circular Buffer

Readers-writers problem
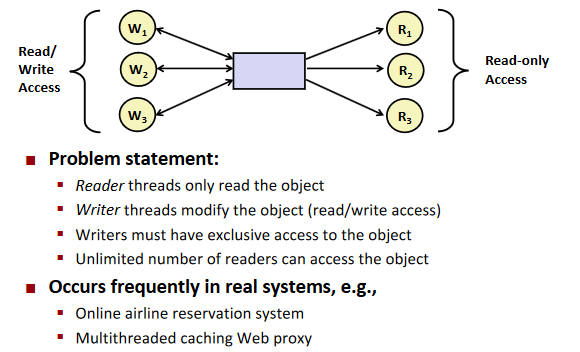
Other concurrency issues
Thread safety

Races

Deadlocks
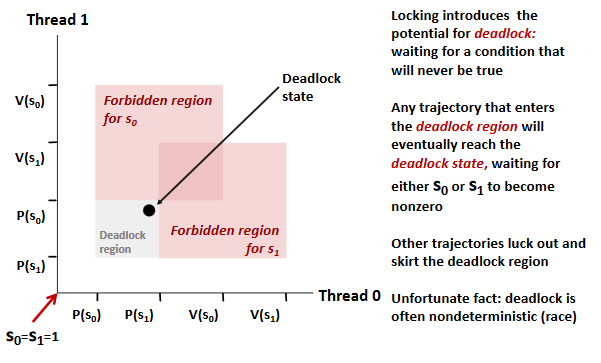
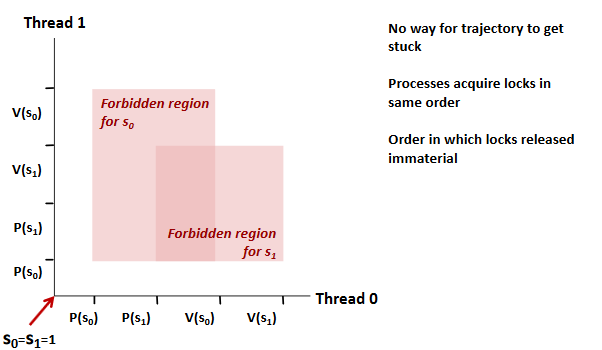
Avoid:
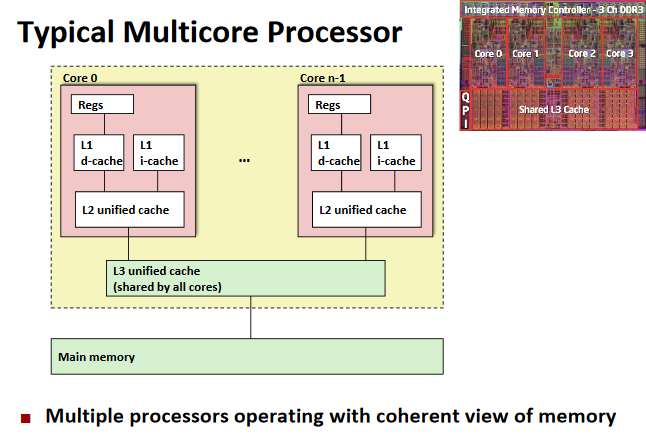
Thread-Level Parallelism
Longer term perspective. Think bigger!
Today

Just see the video.
Future of Computing
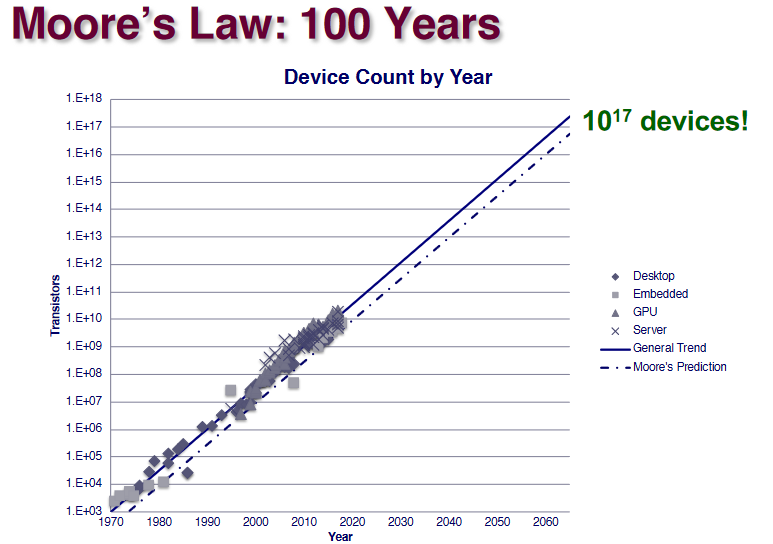
Moore’s Law
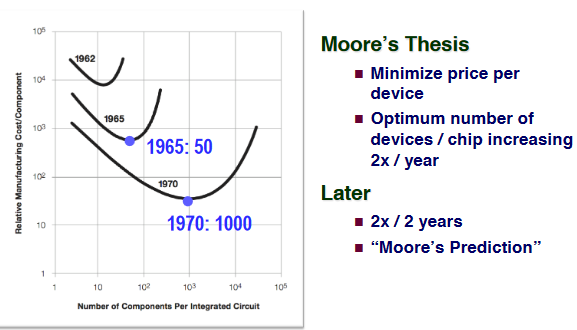
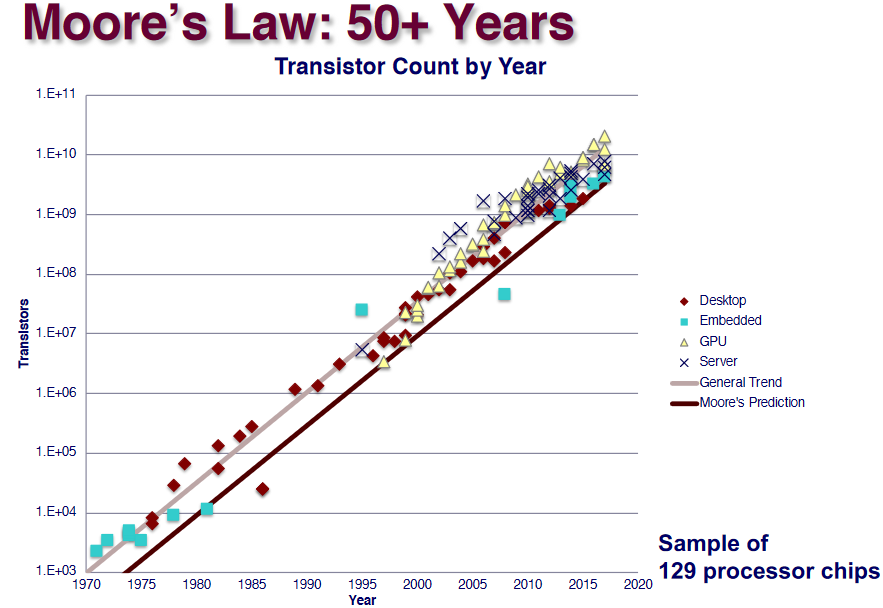
The blue ones are actually for celphones.
The general trend is produced by regression.It’s a prediction rather than a law.

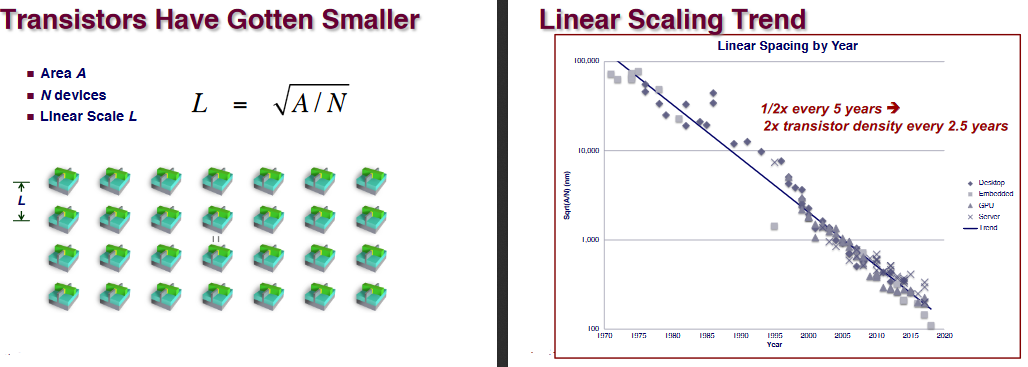
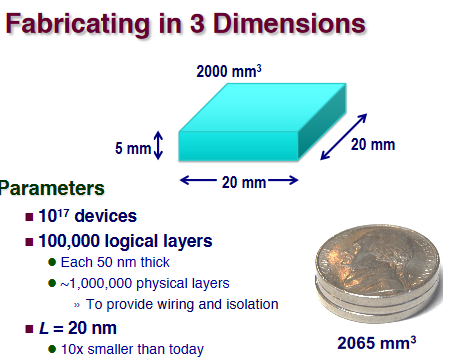
Ex. (3D structure)


High-Performance Computing

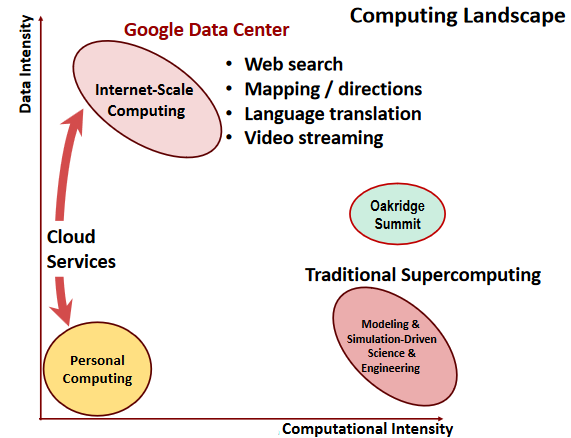
What’s So Special About Big Learning?
This part is available only on 2017 Fall version or after.
Please just see the slides and watch the video.


